Summary
-
vLLM은 PagedAttention을 활용하여, 메모리 활용률은 20~38%에서 100% 가까이로 향상 시켰고, throughput은 2~4배 향상됨
-
GPU 메모리를 OS처럼 사용하는 Block Table Translation 적용하여 메모리 효율화 향상
-
Long Context 혹은 GPU 비용 최적화를 위해서는 vLLM 사용이 필수적임
LLM을 실제 서비스에 올려본 경험이 한번 쯤이라도 있다면 GPU 메모리는 아직 남아 있는데, batch size를 늘리면 갑자기 OOM(Out of Memory) 오류가 발생하는 현상을 겪어보신 적이 있을 겁니다.
이번 포스팅에서 소개할 vLLM은 기존 서빙 방식에서 GPU 메모리가 비효율적으로 사용되는 원인에 분석하고, OS의 가상 메모리(virtual memory) 개념을 LLM 서빙에 접목해 해결책을 제시했습니다.
KV Cache의 Fragmentation
LLM은 자기회귀(autoregressive) 방식으로 토큰을 한 번에 하나씩 생성합니다. 이때, 이전에 생성한 모든 토큰들의 Key-Value(KV) Cache를 보관하면서 다음 토큰을 예측합니다.
예를 들어,
입력:
"기술의 발전은"
출력:
"기술의 발전은" → "빠르다" → "라고" → "느낀다"매번 새로운 토큰을 만들 때마다, 이전 모든 토큰의 KV 정보가 필요하죠.
KV Cache란 LLM에서 생성 과정 중 각 단계의 Key/Value 텐서를 저장해 다음 스텝에서 재사용하는 최적화 기법으로, 중복 연산을 피해 latency를 줄이는 방식입니다.
그렇다면 KV Cache는 GPU 메모리에서 보통 얼만큼의 비율로 사용 될까요?
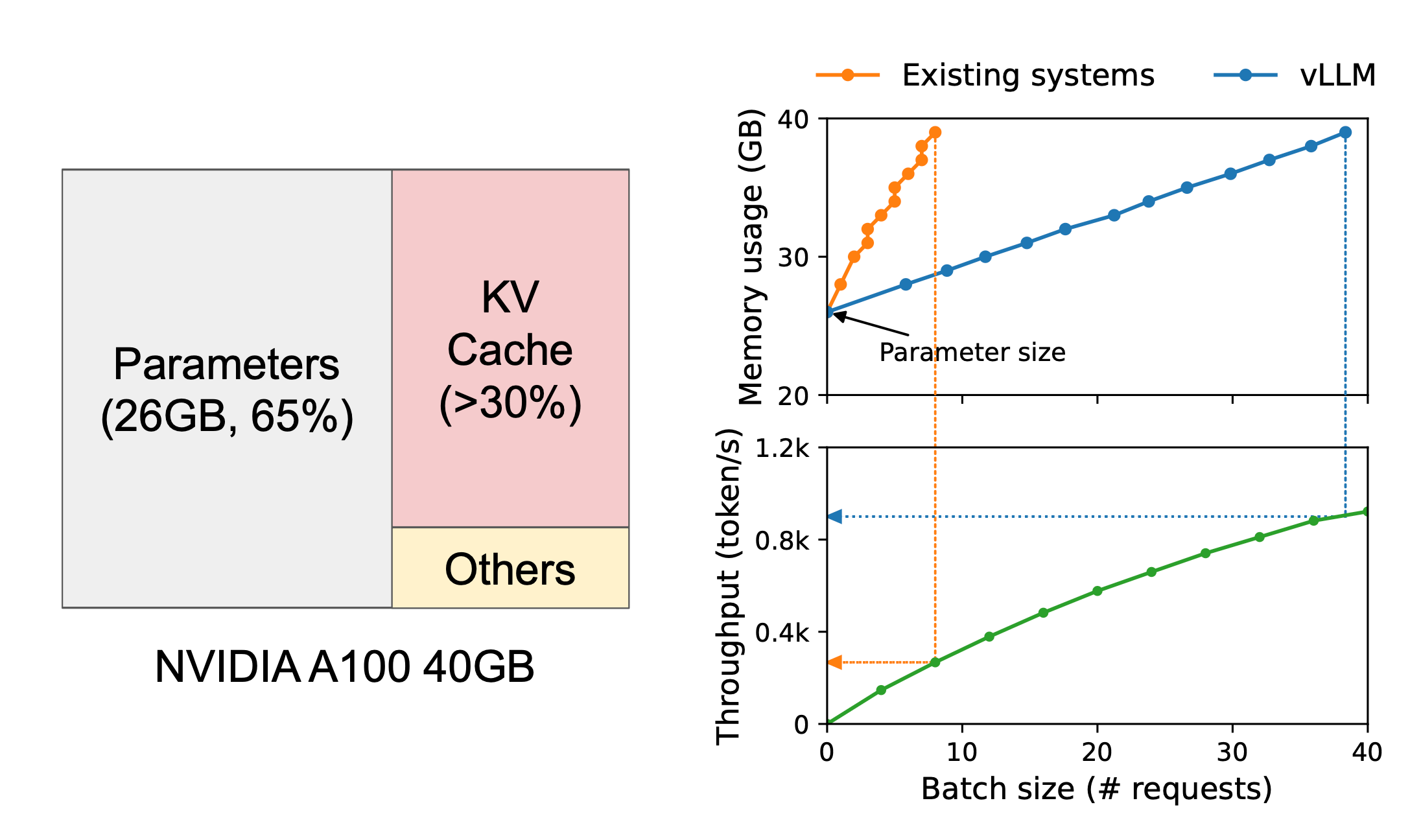
예를 들어, 위 그림의 경우 A100 GPU 40GB에서 13B LLM을 서빙했을 때, 아래와 같이 메모리가 할당됩니다.
- 65%: 모델 Parameters (static)
- 약 30%: KV Cache (dynamic)
- 5%: 기타 연산용 메모리
논문의 저자는 KV Cache가 GPU 메모리의 30% 이상을 차지하는데, 이를 얼마나 효율적으로 활용하고 있는 지에 주목합니다.
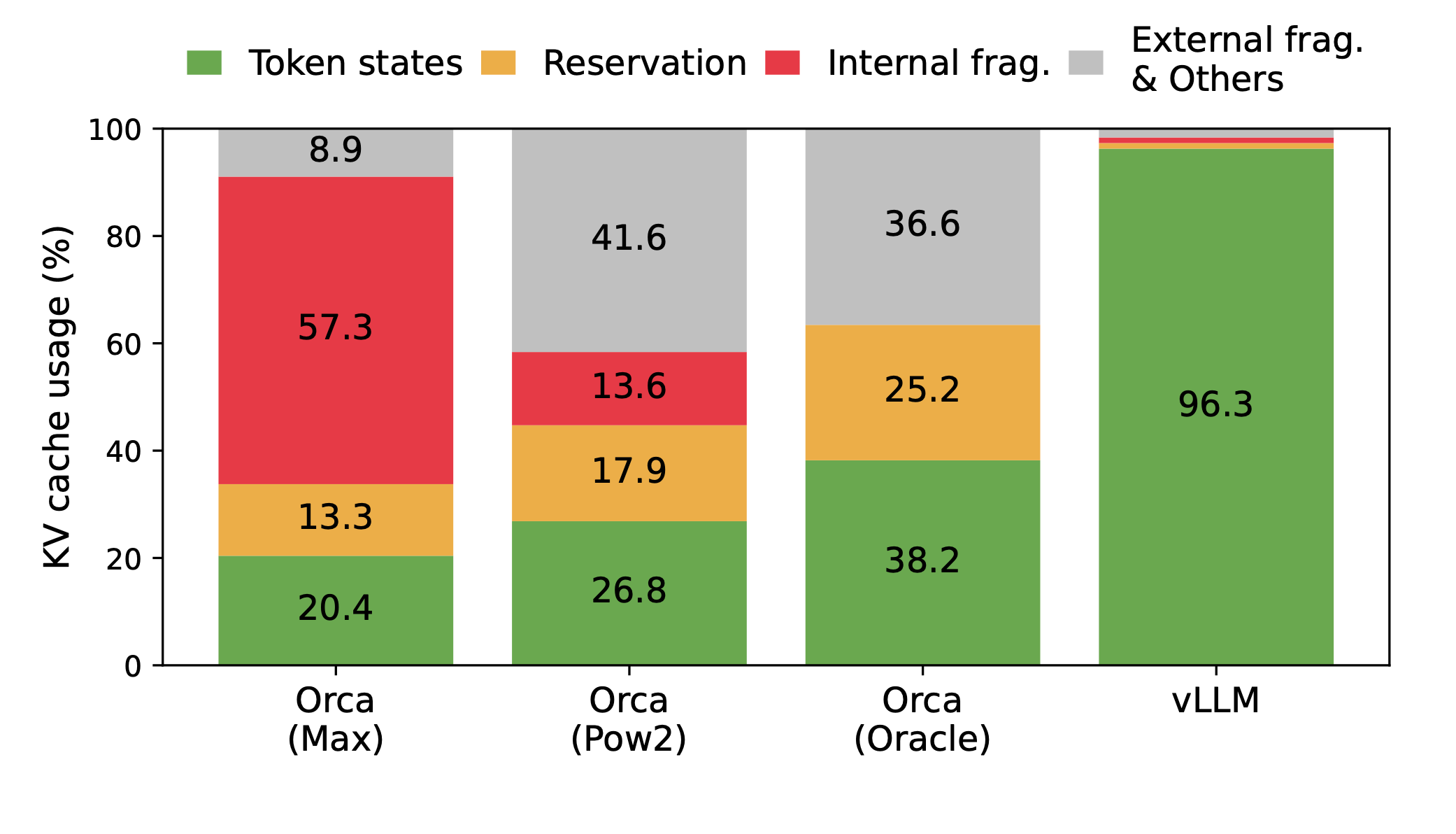
LLM의 경우 토큰을 순차적(sequential)으로 생성하다 보니 메모리 제약이 생기고, GPU 파워를 제대로 못 쓰고, throughput도 떨어집니다.
더군다나 KV Cache는 시간에 따라서 동적으로 늘어났다 줄어들었다(dynamically grows and shrinks)하는 특성으로 인해서 효율적으로 관리하기가 어렵습니다.
기존 LLM serving system들은 KV Cache 메모리를 효율적으로 관리하지 못한다는 점에서 두가지 문제를 지적합니다.
-
메모리 단편화(fragmentation)
- KV캐시를 저장하기 위해 최대 길이만큼 contiguous space에 미리 할당해 버림
- 실제 사용량이 훨씬 적은 경우라도 모두 동일하게 할당 → 대규모 낭비 발생
- 이로 인해 internal, external fragment가 발생함
-
메모리 공유 불가
- Beam Search처럼 토큰 시퀀스를 공유하는 경우에도 매번 별도 메모리 공간을 만들어 중복 저장해야 함
결과론적으로, GPU 메모리 사용 효율이 심각하게 떨어지고, OOM 발생 빈도가 높아집니다.

메모리 단편화(fragmentation)에 대해서 좀 더 자세히 살펴보겠습니다.
예를 들어, 위 그림에서 요청 A(최대 2,048 토큰)와 요청 B(최대 512 토큰)를 가정할 때, 미리 메모리를 할당하는 방식은 아래와 같이 3가지 메모리 낭비 문제가 발생합니다.
-
Reserved slots for future token (다른 요청을 막는 점유)
- 토큰이 늘어날 것을 대비해 여유 공간(reserved space)을 미리 잡아두지만, 이 공간은 대부분의 시간 동안 비어 있는 채로 점유
-
Internal fragmentation due to over-provisioning (요청 완료 후 확인되는 낭비)
- “maximum sequence length”에 맞춰 과도하게 메모리가 할당되면서, 남는 내부 공간은 요청 완료 후에야 fragment였다는 것을 알 수 있음
-
External fragmentation from the memory allocator (즉시 확인 가능한 낭비)
- 메모리가 조각조각 나뉘어서 전체적으로는 충분한데 연속된 큰 공간을 할당할 수 없는 문제
- 예를 들어,
| KV-A | 빈2GB | KV-B | 빈3GB | KV-C | 빈3GB |일때, 총 빈공간은 8GB이지만, 최대 연속된 공간은 3GB이므로 4GB이상의 요청은 실패됨
결과적으로, 기존 서빙 시스템의 경우 실제 메모리 효율성이 **20.4%**까지 떨어질 수 있습니다!
즉, 엄청난 메모리 낭비가 발생하고 있었다는 것입니다.
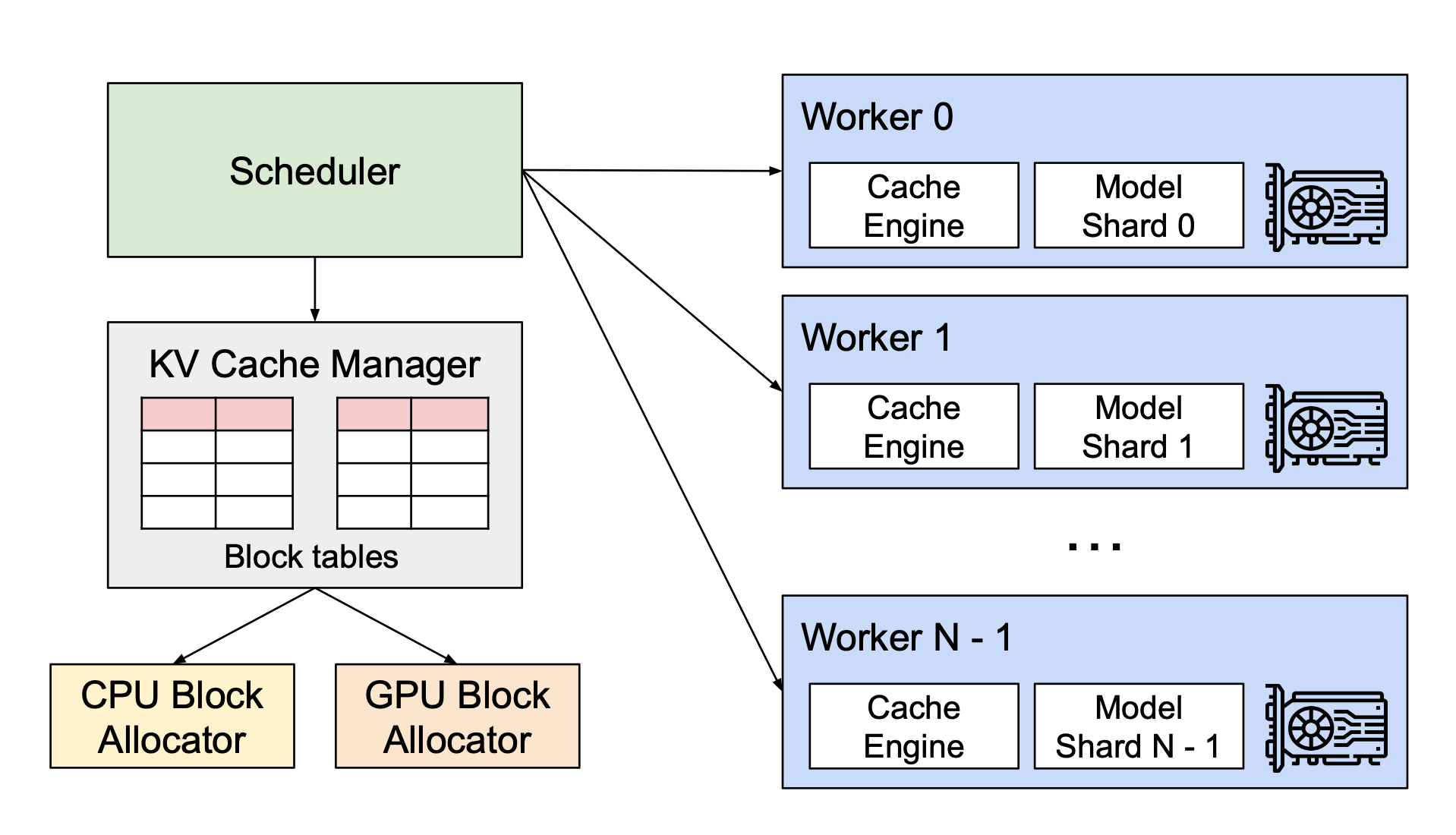
해당 논문에서는 운영체제(OS)의 virtual memory + paging techniques에서 아이디어를 얻어서 문제를 해결했다고 합니다. 이 핵심 아이디어를 좀 더 자세히 살펴보겠습니다.
핵심 아이디어
| 운영체제 개념 | vLLM 적용 |
|---|---|
| 프로세스 (Process) | 요청 (Request) |
| 페이지 (Pages) | KV 블록 (Block) |
| 바이트 (Byte) | 토큰 (Token) |
| 가상 메모리 (virtual memory) | flexible KV Cache 관리 |
- 메모리를 토큰 단위가 아닌 블록 단위로 배치
- 실제로 필요한 시점에만 동적 할당 (on-demand)
- 서로 겹치는 구간은 여러 요청이 공유 가능
즉, 논리적으로는 연속이지만, 물리적으로는 흩어진 KV Cache 구조가 되는 셈입니다.
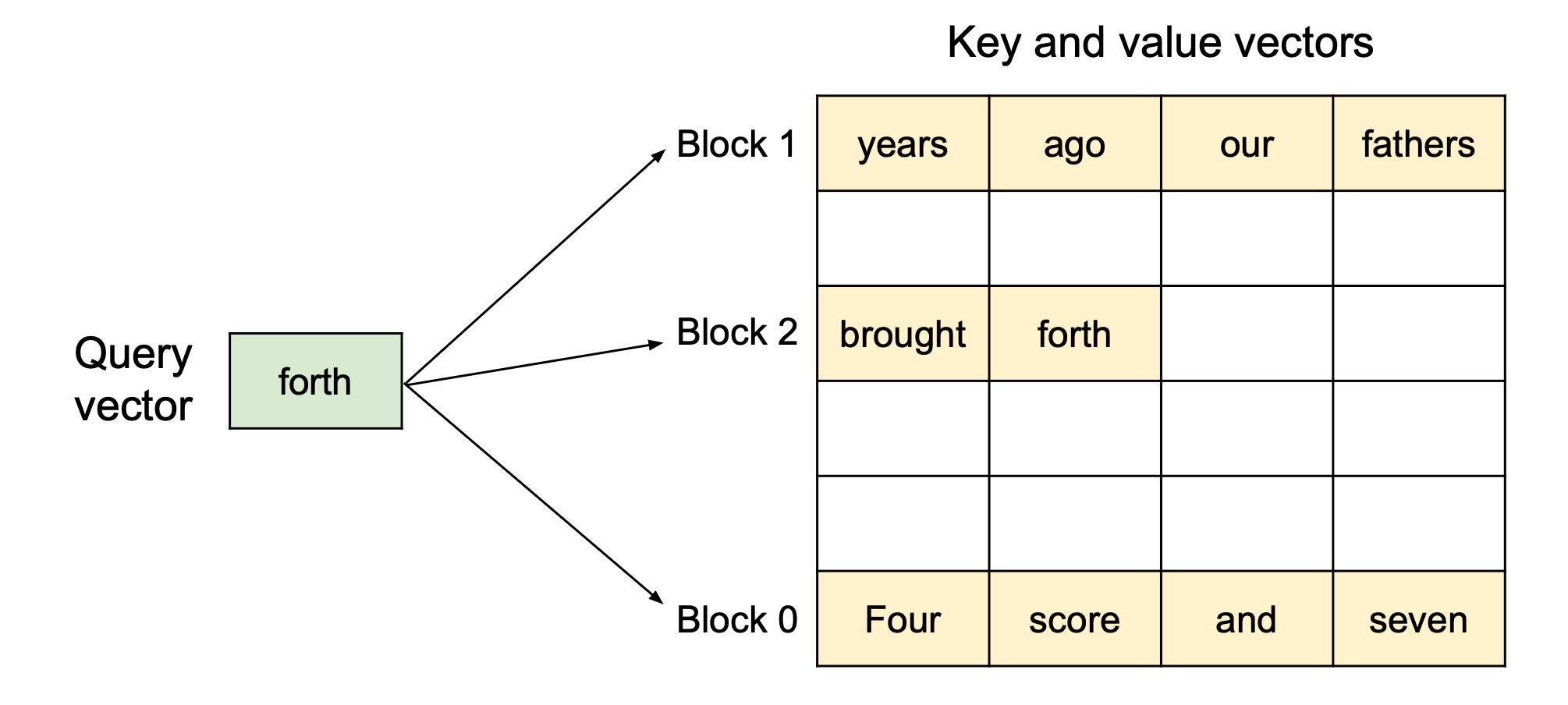
기존 방식에서는 요청마다 긴 최대 길이(예: 2,048토큰)를 통째로 할당했습니다. 사용자가 실제로는 100토큰만 생성하더라도, GPU 메모리에는 2,048칸 전부가 점유되는 방식이죠.
반면 PagedAttention은 KV Cache를 작은 블록 단위로 쪼개 필요할 때마다 동적으로 할당합니다.
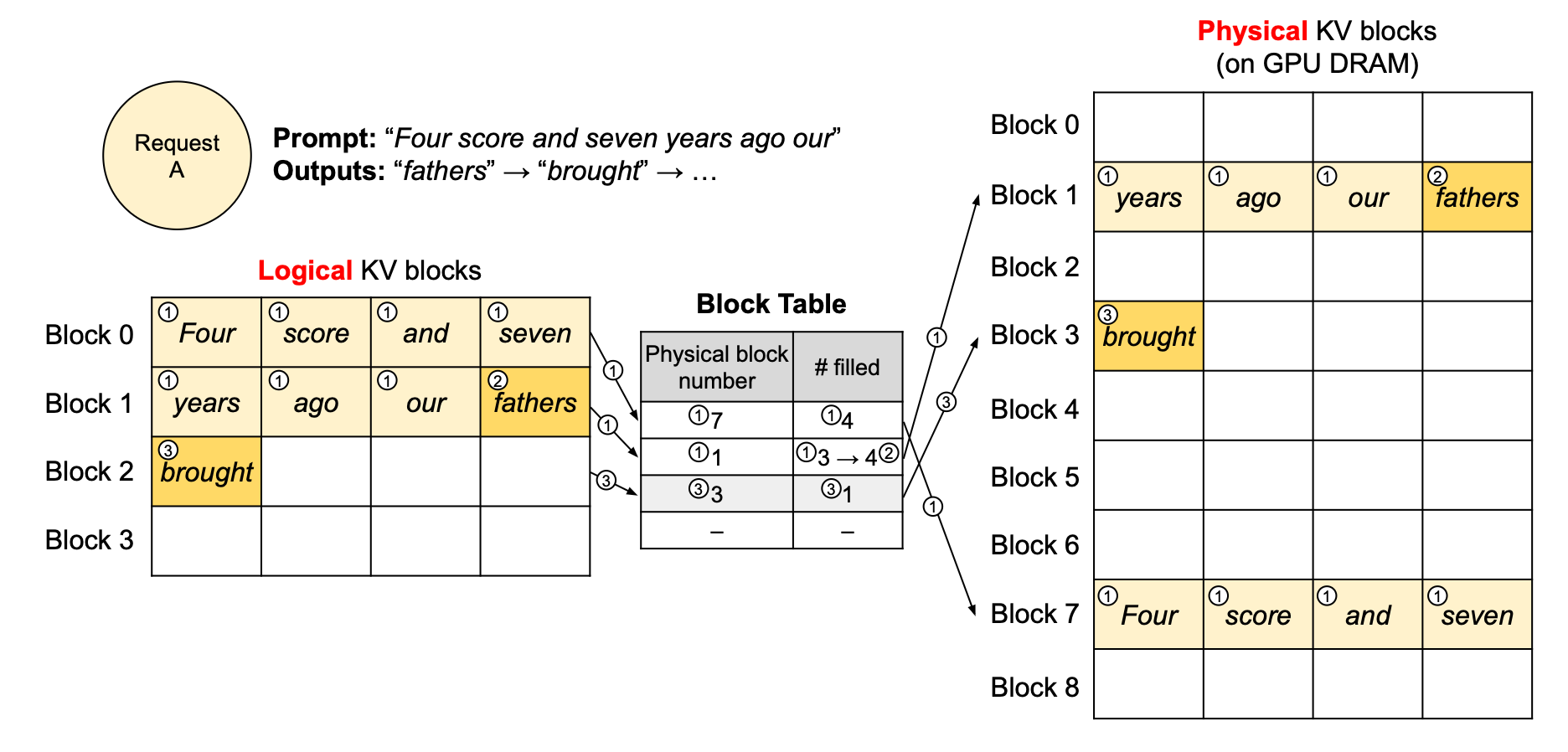
예를 들어,
- Block 0: [“Four”, “score”, “and”, “seven”]
- Block 1: [“years”, “ago”, …]
이 블록들은 전혀 다른 주소(예: GPU 메모리 0x1000, 0x3000 등)에 흩어져 있을 수 있습니다. 하지만 논리적으로 연결해 관리하기 때문에 모델 입장에서는 연속된 시퀀스처럼 동작합니다.
기존의 LLM 서빙 시스템은 KV Cache를 “한 줄로 쭉 이어 붙여서” 저장합니다.
- 논리적으로 순서가 연속이면 → 물리적으로도 연속이어야 하는 구조죠.
- 하지만 이렇게 하면 빈 공간이 생기면 그대로 낭비됩니다.
vLLM의 아이디어는 OS의 가상 메모리와 같습니다.
- 논리적 블록(Logical Block): 토큰들이 순서대로 들어가는 “가상 메모리 내 page”와 비슷함
- 물리적 블록(Physical Block): 실제 GPU 메모리 상의 위치 (여기저기 퍼져 있어도 상관 없음)
- Block Table: 논리 블록 ↔ 물리 블록을 매핑해주는 일종의 페이지 테이블
즉, 사용자는 연속된 메모리처럼 쓰지만, 실제 GPU 메모리에서는 조각조각 배치됩니다.
이러한 PagedAttention 방식은 크게 3가지 장점을 가지고 있습니다.
PagedAttention의 3가지 장점
장점 1. 메모리 낭비 최소화
- vLLM에서는 블록 단위로 on-demand 할당하므로, 최대 낭비치가 “1 Block”에 불과합니다.
장점 2. 배치 효율 극대화
- 메모리를 촘촘히, 유연하게 쓸 수 있어서 throughput이 최대 4배 증가합니다.
- 긴 시퀀스나 Beam Search 같은 복잡한 디코딩 알고리즘에서 성능 차이가 더 극적입니다.
장점 3. 메모리 공유 가능
- Beam Search 같은 경우, 여러 개의 후보 시퀀스가 초반 몇 개 토큰을 공유합니다.
- 기존 시스템: 각 시퀀스마다 별도 공간에 중복 저장 → 비효율
- vLLM: 같은 물리 블록을 여러 논리 블록이 참조 → 중복 저장 없음
결론
이번 포스팅에서는 vLLM의 핵심 기술인 PagedAttention에 대해 살펴보았습니다.
결국 PagedAttention은 기존 OS의 가상 메모리 기법을 LLM에 적용한 것이라고 할 수 있습니다. 메모리 활용률은 20~38%에서 거의 100% 가까이로 향상 시켰고, throughput은 2~4배 향상되었습니다.
이번 gpt-oss가 공개될 때도 OpenAI와 파트너쉽을 맺고, gptoss 전용 vllm 이미지를 공개한 걸로 봐서 사실상 업계 표준으로 자리매김 하고 있는게 아닌가 싶습니다. 물론, SGLang과 속도 측면에서 많이 비교가 되기는 하지만, 아직까지는 vLLM이 안정성 측면에서 더 우수하다고 생각됩니다.
다음에 기회가 되면 vLLM 활용 방식도 포스팅할 예정입니다.