GANomaly 논문을 읽고 정리한 포스트입니다.
Introduction
다양한 Computer vision task의 유망한 성능에도 불구하고 Supervised approach는 방대한 labeled dataset을 요구합니다. 그러나 현실 세계의 문제에서 우리가 관심있어하는 unusual classes는 충분하지 못합니다.
- Supervised learning의 단점은 다음과 같습니다.
- labeled dataset이 많아야한다.
- 학습되지 않은 데이터가 튀어나오면 예측 불가능하다.
대신에 anomaly detection은 unusual한 데이터가 아닌 normal한 데이터를 학습해서 abnormal한 데이터를 식별할 수 있습니다.

예를 들어 위의 사진 처럼 공항 캐리어의 X-ray 사진에서 칼과 같은 anomalous 한 데이터를 식별할 수 있을 것입니다.
즉, 모델은 normal samples인 X와 bnormal dataset인 D가 주어졌을때, 모델 f는 noraml samples의 distribution인 Px를 학습합니다. testing을 할때는 test examples의 anomaly score인 A(x)를 추출하여 abnormal을 detecting합니다.
이 Paper의 목적은 다음과 같습니다.
-
semi-supervised anomaly detection
- encoder-decoder-encoder pipeline 내에 adversarial auto-encode를 사용하여 기존의 접근법보다 우수한 성능을 낸다.
-
efficacy
- statistically와 computationally으로 더 나은 성능을 제공하는 anomaly detection이다.
-
reproducibility
- 코드를 통해 결과를 재현할 수 있는 간단하고 효과적인 알고리즘을 사용할 수 있다.
Our Approach: GANomaly
GANomaly를 보기전에 이전의 논문은 AnoGAN을 한번 보고 갑시다.
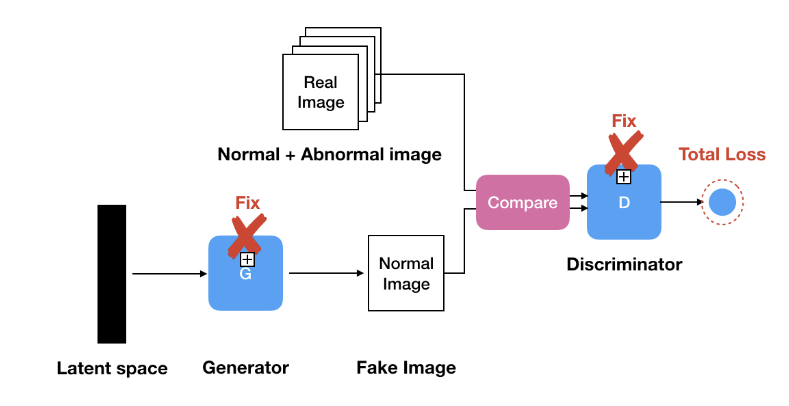
AnoGAN의 경우 Generatir와 Discriminator의 weight를 Fixed 시켜주고 loss 가 최소가 되도록 학습을 진행합니다. 즉 (1) normal한 데이터로 GAN을 학습 시키는 과정과 (2)생성된 이미지와 입력 이미지를 비교하여 anomaly score를 구하는 과정이 따로 분리되어 있습니다.
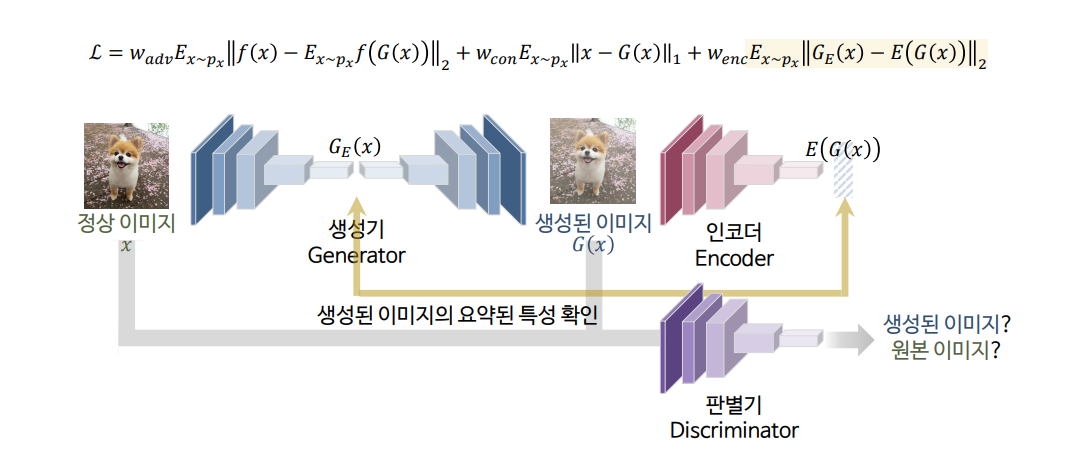
GANomaly 모델은 이미지를 생성하는 과정과 latent space를 학습하는 과정을 한 번에 진행하고자 제안되었습니다.
그래서 모델의 구조에 Generator과 Discriminator 이외에 인코더 부분이 추가되었습니다.
모델 순서는 다음과 같습니다.
- normal 이미지를 모델의 input으로 받아서 compress한 후에 다시 reconstructed하여 새로운 이미지를 생성한다.
- Discriminator 모델은 기존과 동일하게 nomal 이미지와 생성된 이미지를 받아서 구분한다.
- 새롭게 추가된 인코더 모델은 생성된 이미지를 다시 compress 하여 latent vector를 추출한다.
모델을 이렇게 구성한 이유가 있습니다. 그 이유를 loss function을 통해 알아보도록 하겠습니다.
- Adversarial Loss
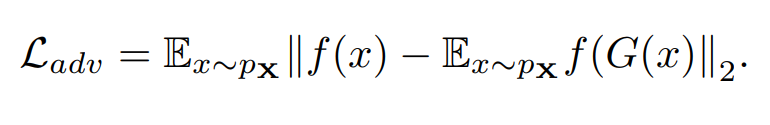
첫번째 term은 Discriminator는 입력 데이터들의 확률 분포를 파악해서 True/False를 판단해줄 수 있습니다. Adversarial Loss는 G(x)의 Manifold 또는 Data Distribution에 잘 Mapping되도록 패널티를 부과하는 Loss 입니다.
- Contextual Loss.
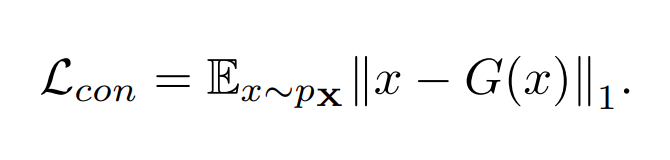
두번째 term은 normal 이미지와 G(x) 사이에서 다른 부분이 있는 지 차이를 비교하는 과정입니다. 즉 normal 이미지로부터 속성을 잘 요약한 후에 잘 보존하고 있는지 파악합니다.
- Encoder Loss
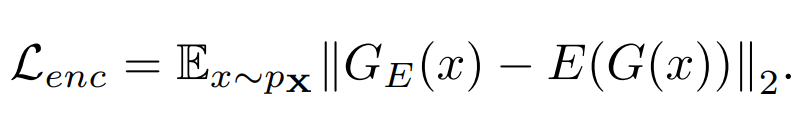
마지막으로 latent vector 간의 비교입니다. 앞서 Ganomaly 모델에서 특별하게 추가한 인코더 부분은 latent 벡터를 만들어준다고 했습니다. 해당 모델에서 latent vector를 생성하는 부분은 두곳 입니다.
- Generator 모델에서 normal 이미지의 latent vector를 추출
- 새롭게 추가된 인코더에서 생성된 이미지의 latent vector를 추출
저희의 목표는 이 두가지 latent vector가 유사해야된다는 겁니다. 유사하지 않다면 다른 이미지가 됨으로 normal하지 않은 unusual(=abnormal)한 데이터라고 판단할 수 있습니다.
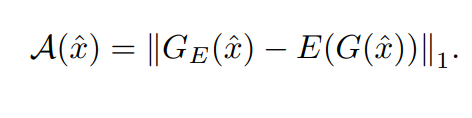
이제 Anomaly score인 A(x)를 앞에서 설명드린 두 latent vector의 차이로 계산할 수 있습니다. abnomal한 이미지가 들어오면 latent vector간의 차이가 크기 때문에 A(x) 또한 큰 값을 가지게 될 것입니다.
Experimental Setup
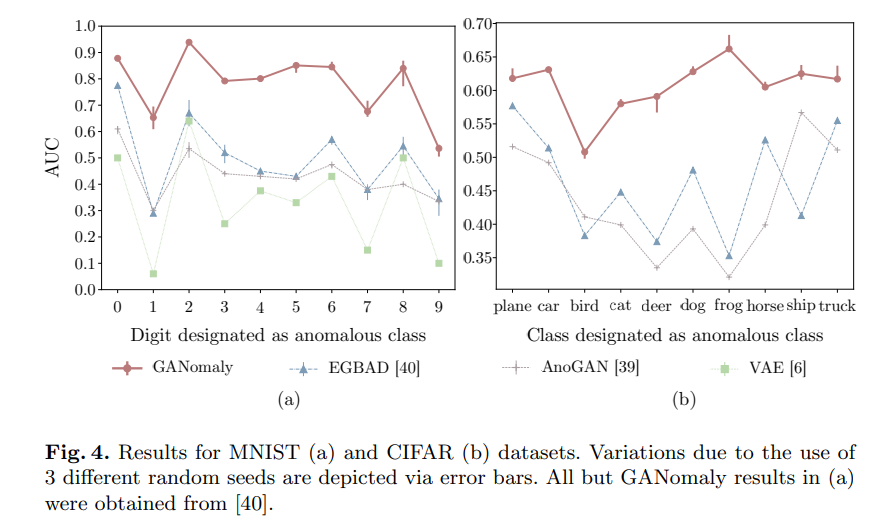
위의 그래프는 MNIST와 CIFAR로 벤치마크 한 결과입니다. GANomaly의 경우 이전의 모델에 비해 AUC가 높은 것을 확인할 수 있습니다.
Result
데이터셋의 모습
University Baggage Anomaly Dataset — (UBA)

Full Firearm vs. Operational Benign — (FFOB).

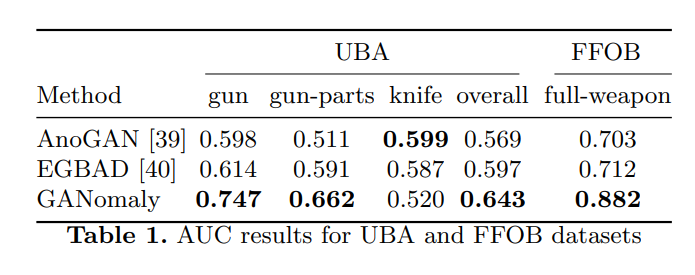
클래스에 따라서 달라질 때도 있지만 전반적으로 GANomaly가 우수한 성적을 보입니다.
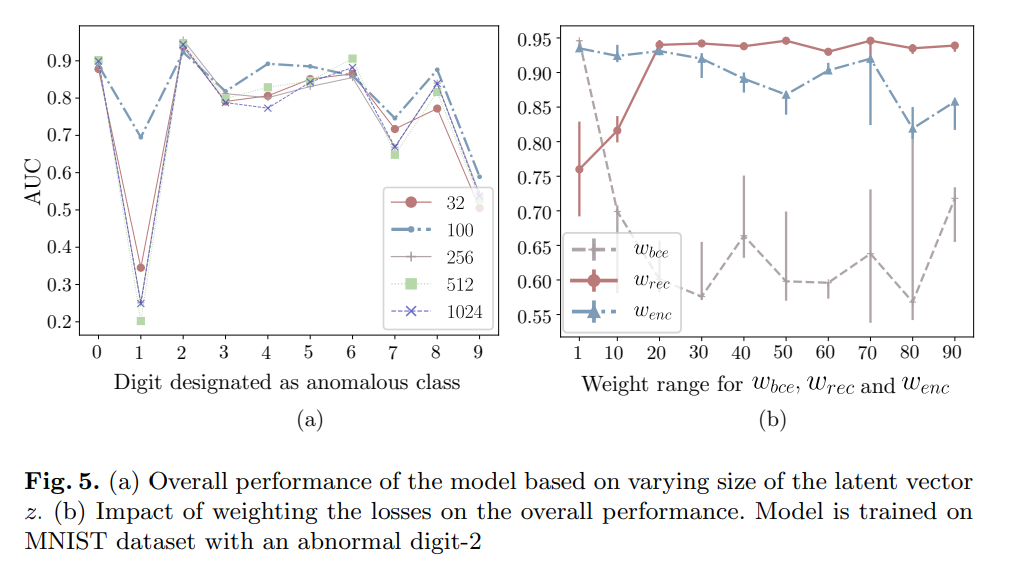
위 그림은 hyper-parameter에 따른 전체 성능의 영향을 볼 수 있습니다. 예를 들어서 (a)의 그래프를 보면 MNIST dataset의 최적의 latent vector z의 개수는 100이됩니다. 또한 abnomal이 2일 때 Wbce = 1, Wrec = 50, Wenc = 1이면 가장 높은 AUC를 달성합니다.
Conclusion
- 우리는 새로운 네트워크인 encoder-decoder-encoder architectural model for general anomaly detection을 소개했습니다.
- 데이터 세트 벤치마크에 대한 실험을 통해 기존의 SOTA GAN-based과 traditional autoencoder-based anomaly detection approaches보다 성능이 우수한 걸 알 수 있습니다.
- 향후에는 GAN의 training 성능을 높여줄 수 있는 GAN optimization을 활용할 예정이다.