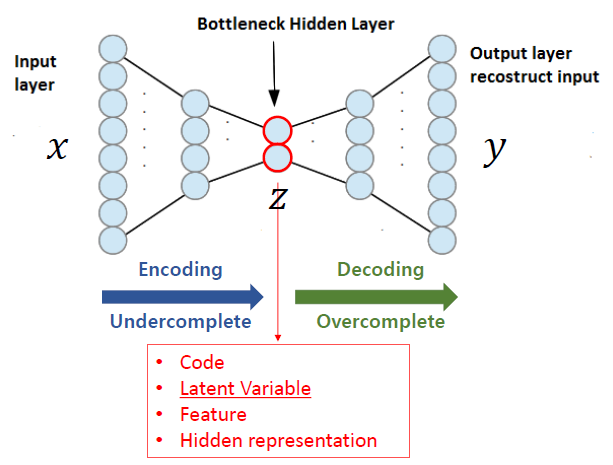
1. 오토인코더란?
오토인코더(Auto Encoder)란 입력이 들어왔을 때, 해당 입력 데이터를 최대한 compression 시킨 후, compressed data를 다시 본래의 입력 형태로 복원 시키는 신경망입니다. 이때, 데이터를 압축하는 부분을 Encoder라고 하고, 복원하는 부분을 Decoder라고 부릅니다. 압축 과정에서 추출한 의미 있는 데이터 Z를 보통 latent vector라고 부르고, 이 외에도 ‘latent variable’, ‘latent vector’, ‘code’, ‘feature’등과 같은 용어로 부릅니다.
2. 왜 이름이 오토인코더일까?
그렇다면, 왜 우리는 이 모델을 “Auto Encoder”라고 부르게 되었을까요? 그 이유는 다음 그림을 예시로 들어 설명 드리겠습니다.

위의 그림은 Auto Encoder의 결과를 시각화한 이미지 입니다. 자세히 보면 y축으로 두께 변하고, x축으로는 기울기가 변하는 것을 확인할 수 있습니다. 이를 통해 이 모델의 latent vector는 두께, 회전, Class로 정의되어 있다는 것을 알 수 있습니다.
여기서 중요한 점은 Auto Encoder가 출력하는 latent vector를 미리 알 수 없다는 사실입니다. 우리는 단지 3차원으로 데이터를 압축하라는 명령을 내렸을 뿐, 이후에는 모델이 알아서 중요한 latent vector를 찾아 준 것입니다. 즉, Encoder 모델이 학습을 통해 자동적(automatically)으로 latent vector를 찾아준 것이죠.
그래서 우리는 고차원 데이터를 잘 표현해주는 latent vector를 자동으로 추출해주는 모델을 Auto Encoder라 부릅니다.
오토인코더에서 Decoder는 latent vector를 잘 찾기 위한 도우미 역할을 합니다. 다시 말해서 Decoder는 거둘 뿐, Encoder에 초점이 맞춰져 있습니다. 우리의 목적은 의미 있는 latent vector를 찾는 것이니까요!
3. Auto Encoder의 다양한 관점
Auto Encoder는 다양한 관점에서 해석이 가능합니다. 다시 말해, 다양한 분야에서 사용될 수 있다는 뜻이죠. 일반적으로 4가지 관점이 있습니다. 이에 대해서 다음 글을 통해 하나씩 알아보도록 하겠습니다.
- Unsupervised learning
- Maximum Likelihood density estimation
- Manifold learning
- Generative model learning
3-1. Unsupervised Learning (Feat. Self-Supervised Learning)
Supervised learning
Unsupervised learning을 보기 전에 먼저 Supervised learning을 간단하게 짚고 넘어 가겠습니다. Supervised learning은 label을 이용해서 모델을 학습하는 방식을 말합니다. 입력 데이터에 대한 출력 값이 무엇인지 대한 사전 지식이 있기 때문에 학습도 쉽습니다. CNN의 학습 순서를 간단히 설명하면 다음과 같습니다.
- Training dataset을 CNN 모델에 입력해 줍니다.
- CNN 모델이 입력 이미지에 대해 prediction을 합니다. 이 때, prediction 결과로는 판단한 클래스(=Class)와 해당 클래스로 판단 할 때의 확신 정도(=Probability)를 출력합니다.
- 그리고, prediction 한 결과와 Label을 비교하여 loss를 출력한 후, backpropagation으로 학습을 진행합니다.

Unsupervised learning
Unsupervised Learning은 Supervised learning과 다르게 label 데이터가 없이 인공지능 모델을 학습을 합니다. 이를 통해 데이터 그 자체에 숨겨져 있는 패턴을 발견하는 것이 목표입니다.
아래와 같이 MNIST 데이터의 compressed data(=latent vectors)를 찾기 위해서 사용하는 Auto-Encoder 학습 방식은 Unsupervised learning이라고 할 수 있습니다. 따로 label 정보를 지정하지 않았기 때문입니다.
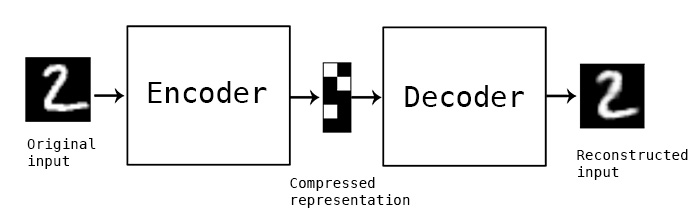
2018년 이후로는 Unsupervised Learning이라는 용어를 Self-Supervised Learning(SSL) 으로 바꾸어 사용하고 있습니다. Self-Supervised Learning에 대해서는 추후에 따로 글을 작성하여 링크를 걸어 놓도록 하겠습니다.
3-2. Maximum Likelihood density estimation
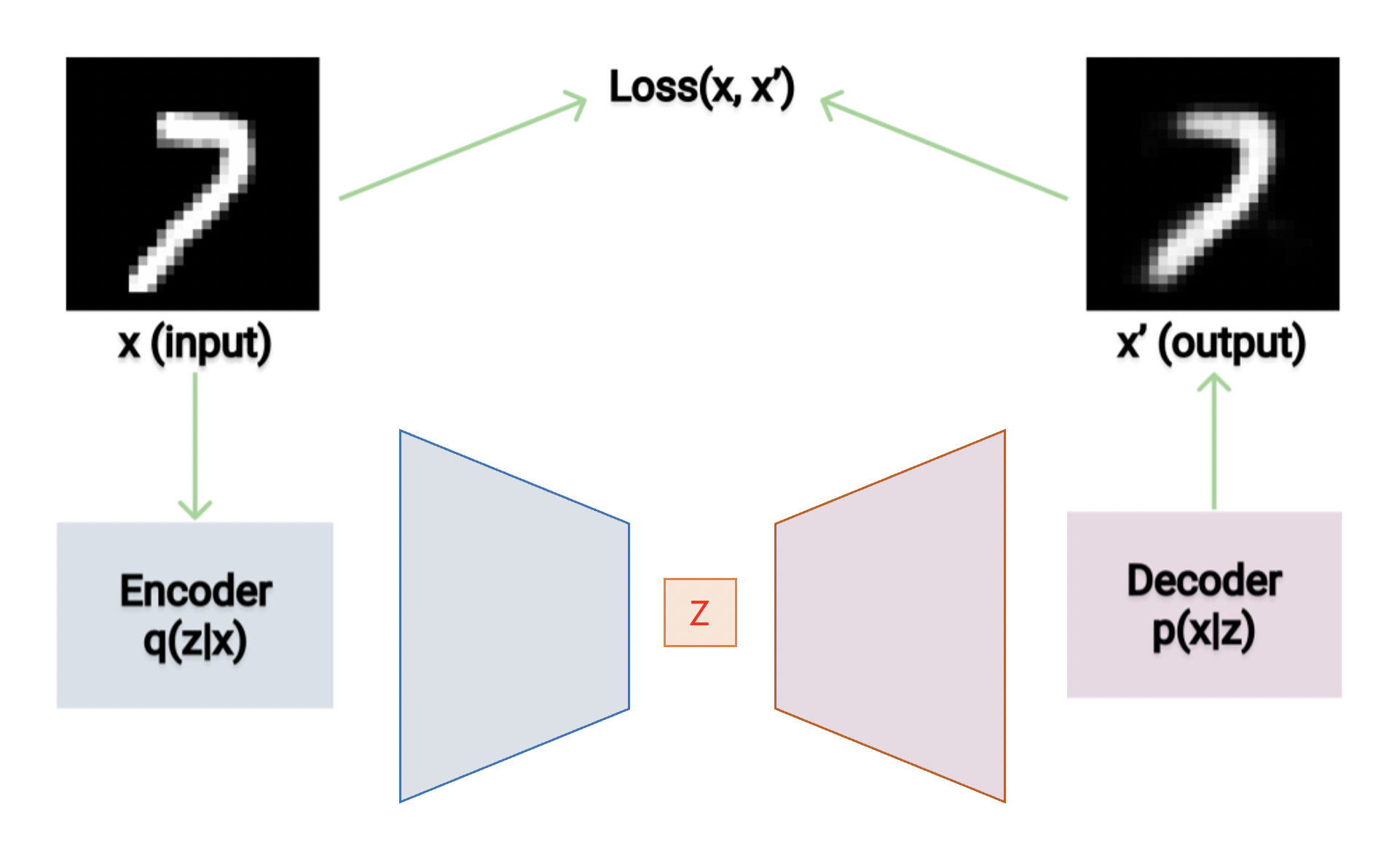
Auto Encoder는 Input X값을 축소시킨 뒤, 다시 재현해내는 기능을 가지고 있습니다. 위와 같이 7이라는 숫자를 입력으로 넣어서 다시 7이라는 숫자를 재현 시킬 수 있습니다.
이때 Decoder가 얼마나 복원을 잘했는지 알기 위해서는 입력된 7과 재현된 7의 사진의 차이를 보면 됩니다. 하지만 이럴 경우 오차가 매우 클 것으로 예상이 됩니다. 픽셀 단위로 재현된 숫자를 분석하면 그 차이가 매우 다르기 때문입니다.
이는 단순히 생각해도 비효율적인 학습 방법이 됩니다. 사람의 시각에서 보면 같은 7이라는 숫자여도 컴퓨터의 관점에서는 완전히 다른 숫자로 인식하기 때문입니다. 이를 해결하기 위한 방식중 하나가 MLE(Maximum Likelihood density estimation)입니다.
이전 예시는 단순히 입력과 출력이 같기를 바라는 관점이었고, MLE는 입력과 출력이 같아질 확률이 최대가 되길 바라는 관점 입니다. 다소 어려운 개념이지만, 확률이라는 단어에 중점을 두면 됩니다. 관측된 샘플들을 존재하게 할만한 가능성(확률)을 최대화 시키는 값을 찾는 것을 목적으로 합니다. 즉, 최적의 parameter를 찾는 과정이라고 이해하면 됩니다.
3-3. Manifold learning
Manifold learning의 한가지 역할 중 하나는 차원 축소 입니다. 굉장히 큰 차원을 저차원으로 줄일 수 있는 역할을 합니다. “2. 왜 이름이 오토인코더일까?” 에서 예시를 든 것처럼, manifold learning을 이용하면 숫자 2의 이미지를 latent vector는 두께, 회전, Class로 차원 축소를 할 수 있습니다.
숫자 2 이미지가 MNIST 데이터(28x28)라고 가정할 때, 784 차원으로 표현 될 수 있습니다. 이를 두께, 회전, Class로 총 3개의 차원으로 축소할 수 있는 것도 데이터를 잘 표현할 수 있는 서브 스페이스를 찾았기 때문입니다.
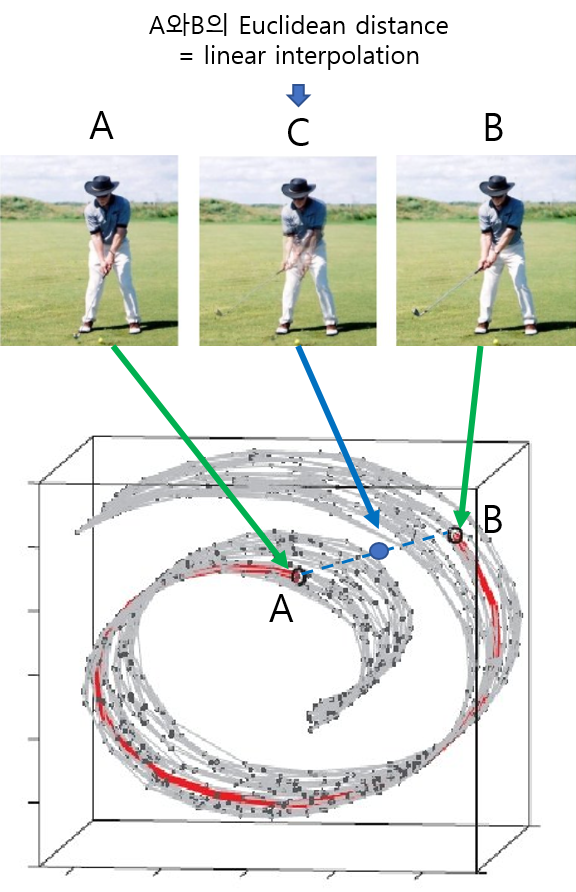
매니폴드 러닝을 많이 사용하는 이유는 가장 중요한 feature를 찾을 수 있다는 장점이 있기 때문입니다. 위의 그림의 경우 모델은 골프를 치는 사람의 중간 모습을 찾고 싶어 합니다. 하지만 사람의 직관에서 가깝다고 생각되는 샘플(A,B)의 실제 Euclidean distance는 멀기 때문에 부자연스러운 이미지가 생성됩니다. 이를 해결하기 위해, 매니폴드 러닝으로 아래 고차원 공간을 잘 표현해 줄 수 있는 저차원 공간을 찾아 Euclidean distance를 구하면 원하는 interpolation 결과를 얻을 수 있습니다.
Reference
https://videolectures.net/deeplearning2015_vincent_autoencoders/ https://awesomeopensource.com/project/hwalsuklee/tensorflow-mnist-CVAE