Summary:
실험 관리를 할 수 있는 W&B와 MLflow를 비교한 글입니다.
동기
최근에는 딥러닝을 학습을 효율적으로 관리할 수 있는 방법에 관심을 갖고 있습니다. 딥러닝 실험을 진행하다 보면 해당 실험의 코드와 학습된 모델의 버전을 관리가 필요합니다. 실험에서 끝나는 것이 아닌, 딥러닝 모델을 서비스로 붙이기 위해서는 배포되는 환경에서도 실험에서 얻었던 결과를 얻을 수 있어야되기 때문입니다. 그렇기에 실험관리 측면에서 ML pipeline을 구축하는 것이 중요합니다.
이번 포스트에서는 효율적인 ML pipeline을 구축하는 방법과 Machine Learning Lifecycle에 독보적인 기능을 가지고 있는 MLflow에 대해서 알아보도록 하겠습니다.
1. ML Pipeline
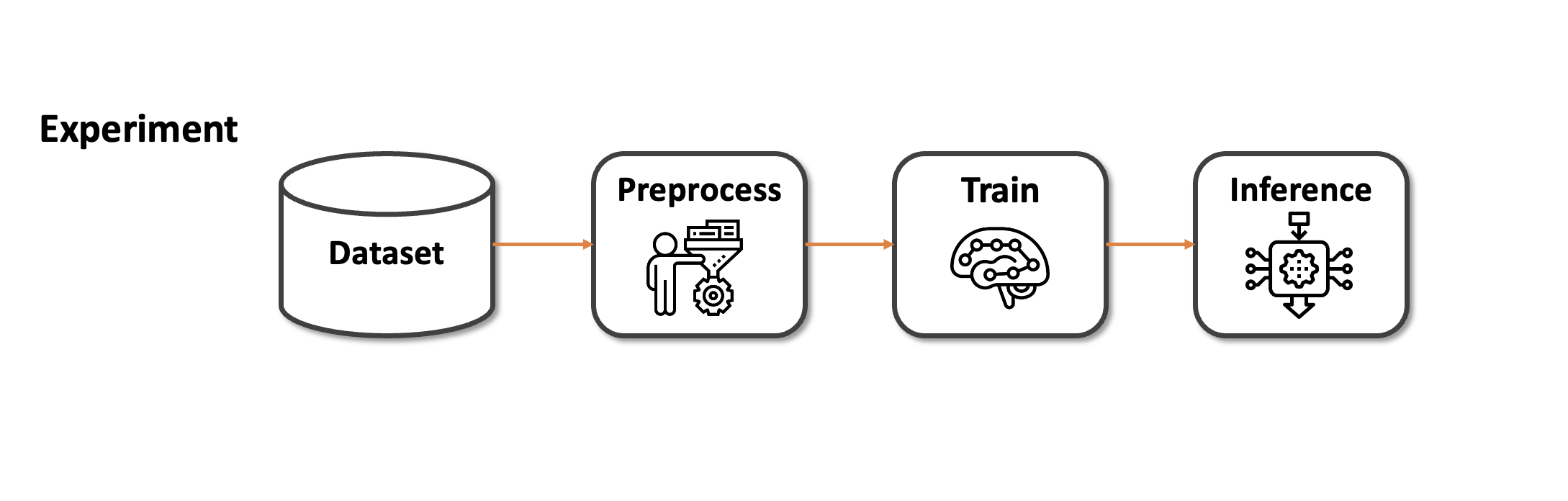
위 그림처럼 구성된 Pipeline은 딥러닝 실험을 위한 간단한 구조입니다. 보통 실험은 데이터 준비, 전처리, 학습, 추론 순으로 진행됩니다. Dataset은 public으로 공개된 데이터셋일 수도 있고, 개인이 준비한 custom 데이터셋일 수도 있습니다.
보통 데이터셋은 실제 환경에서 추출되었기 때문에 딥러닝 모델에 바로 적용하기 어려운 원시(raw) 데이터입니다. 그렇기에 학습을 위한 preprocessing 단계가 필요합니다. 전처리 단계에서는 원하는 feature만 추출하던가, 혹은 원하는 형태로 가공시켜줍니다. 간단한 전처리의 경우 보통 Dataloader에서 가공을 진행합니다.
가공이 완료된 데이터는 본격적으로 학습에 사용이 됩니다. 학습은 Training과 Validation으로 나눠서 진행됩니다. Training은 모델의 성능을 높이는데 초점을 맞추고, Validation은 모델을 평가하는데 초점을 맞춥니다. 최종적으로 모델은 Validation score(or metric)가 높은 model이 선택이 됩니다.
Inference 단계에서는 앞선 학습 과정에서 Validation 성능이 높은 모델을 가져와서 진행을 합니다. Supervised learning의 경우 학습 단계에서는 data와 label이 모두 존재하지만, 추론 단계에서는 label이 존재하지 않을 수도 있습니다. 캐글에서는 submission을 위한 단계가 될 것이고, 서비스의 관점에서는 실시간으로 들어오는 실제 데이터를 위한 단계가 될 것 입니다.
지금까지 설명드린 4개의 단계는 말 그대로 ML pipeline입니다. 하지만 온전한 Machine learning lifecycle을 완성시키기 위해서는 재현성, 생산성, 확장성 측면에서 보충될 필요가 있습니다.
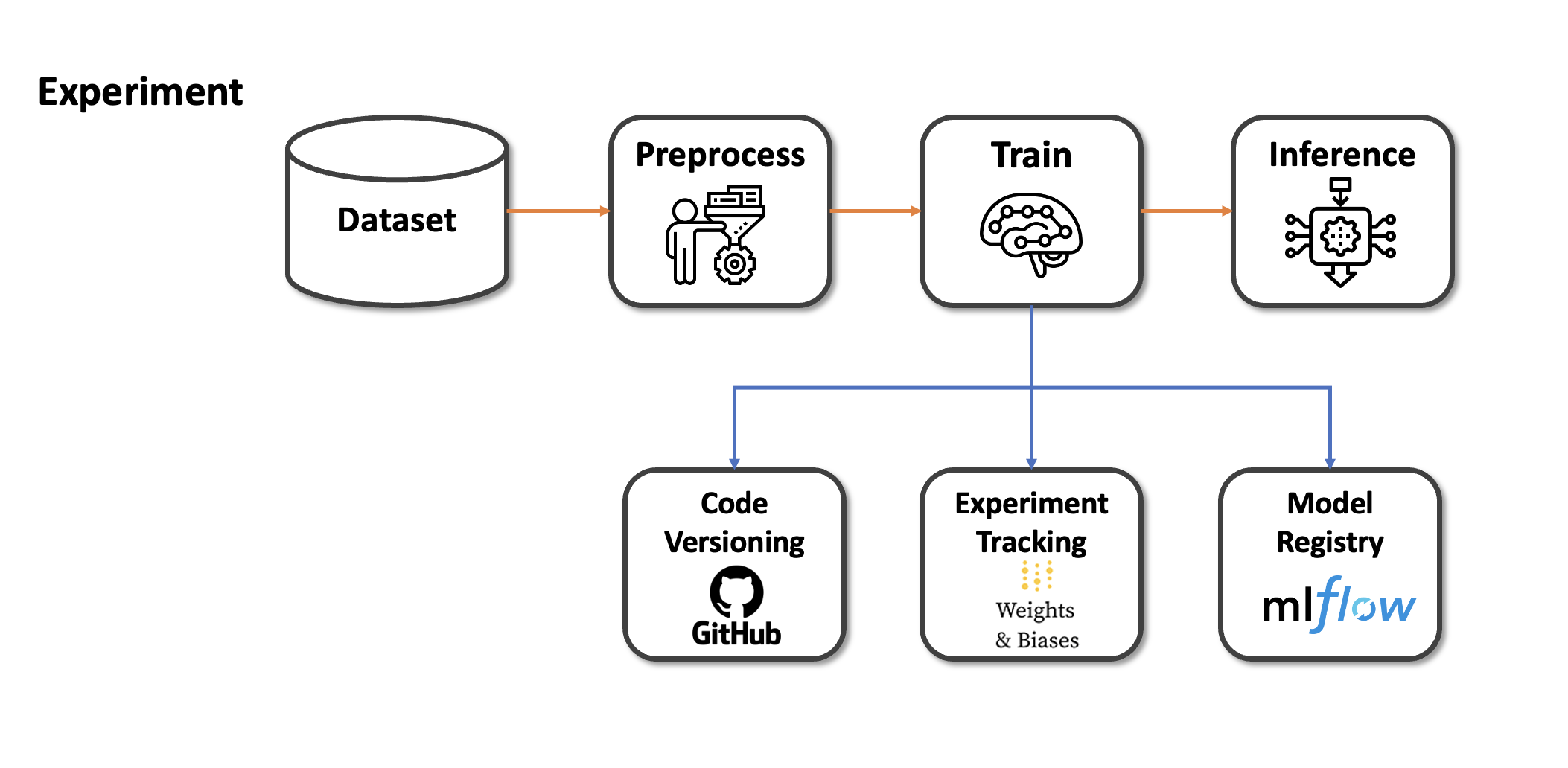
그래서 저는 Machine learning lifecycle을 도와주는 Tool을 사용해서 위에서 언급한 단점을 해결하고자 했습니다. Code 관리의 경우 해당 모델이 어떤 코드에서 학습이 되었는지 형상 관리를 하기 위해 github라는 Tool을 사용하고 있습니다. Git을 통해 코드를 commit하게 되면 해당 시점의 code를 확인할 수 있어서 다음에 실험을 재현하거나 참고할 때 도움이 됩니다.
Experiment Tracking tool인 WandB의 경우 1. WandB란? - 강력한 MLOps Tool에서 설명드린바 있습니다. WandB의 경우 지금까지도 매우 유용하게 사용하는 도구중 하나입니다. 실험 내용을 그래프로 확인할 수 있고, 하이퍼 파라미터 튜닝을 통해 더 높은 성능을 기대할 수 있게 만들어줍니다.
그리고 요즘 많이 사용하고 있는 Tool이 바로 MLflow입니다. MLflow는 재현성, 생산성, 확장성을 모두 고려한 Tool 입니다. 이 때문에 온전한 ML lifecycle을 완성시키기 위해서는 MLflow의 사용이 필수적입니다. 사실 MLflow와 WandB는 겹치는 기능이 다소 존재합니다. 그래서 이번 포스팅애서 두개의 Tool을 비교해보고, MLflow의 사용법을 다음 포스팅부터 차근차근 정리할 예정입니다.
2. WandB vs MLflow 비교

실험 관리 Tool은 크게 experiment tracking oriented tools 혹은 full lifecycle-oriented tools로 분리할 수 있습니다.
Experiment tracking Tool
experiment tracking oriented tools은 실험 관리에 최적화된 Tool입니다.
만약 model의 architecture가 서로 다를 때, 더 좋은 solution을 선택하기 위해선 experiment tracking oriented가 적합합니다.
대표적으로 WandB를 예로 들 수 있습니다.
Full lifecycle Tool
Full lifecycle Tool은 ML Project의 experimentation, reproducibility, deployment, model registry를 관리하기 위한 Tool입니다.
다음 4가지의 관점에서 강력한 장점을 가지고 있습니다.
- Tracking : 파라미터, metric의 결과를 logging 하고 UI로 확인
- Projects : Anaconda나 docker를 사용해서 reproducible하게 만듬
- Models : 동일한 모델을 Docker, Spark, AWS 등에서 쉽게 배치
- Registry : 모델의 전체 lifecycle을 공동으로 관리 API, UI
대표적으로 MLflow를 예로 들 수 있습니다.
각 Tool의 장단점
WandB
장점
- 실험 결과들을 빠르게 비교할 수 있다.
- 다양한 plot을 제공해줘서 다각적으로 분석이 가능하다.
- Report를 작성하여 결과를 공유할 수 있다.
- Sweep을 통해서 Hyper parameter tuning을 할 수 있다.
- 결과를 공유하여 협업 할 수 있다.
단점
- Experiment-tracking 기능만 제공해줘서 deployment가 안된다
- 저장공간이나 인원수를 늘리려면 price를 요구한다.
MLflow
장점
- 마찬가지로 Hyper parameter tuning을 할 수 있다.
- Model serving 단계로 확장 가능성이 있다.
- 모델의 기록이 체계적이다.
- 무료로 이용할 수 있는 Open source tool이다.
- conda와 도커를 이용해서 환경을 동일하게 세팅할 수 있다.
단점
- 실험을 추적하거나 비교하기가 힘들다.
- 실험 횟수가 증가하면 UI가 느려진다.
- Tracking Server를 따로 개방해야한다.
결론
- 개별적인 모델 실험에 있어서 MLflow 보단 W&B가 적합해 보입니다.
- MLflow는 전체적인 lifecycle 구성에 강력한 도구가 됩니다.