Transformer에서 사용되는 Attention 기법이 무엇인지 알아보고 정리한 글입니다.
개요
안녕하세요~! 전부터 읽고 싶었던 “Attention Is All You Need” 논문을 읽을 기회가 생겼어요.
10월부터 5주동안 Transformer 논문 읽고 pytorch로 구현하기 풀잎스쿨을 진행할 예정입니다. 풀잎스쿨은 스터디와 비슷한 방식이기 때문에 두 단어를 혼합해서 사용할게요!
이번 기회에 요즘 대세인 트랜스포머 모델에 대해 완벽하게 이해하는 계기가 되면 좋겠네요. 스터디 방식에 대해서 간략히 설명하면 아래와 같아요.
풀잎 방식
스터디 진행 전
- 스터디 시간 전까지는 꼭 이전 시간에 배운 내용을 포스팅 해오기!
스터디 진행 중
- 논문 읽기는 기본적으로 슬로우 페이퍼 방식으로 진행.
- 진행 중간에 구성원 간에 자유로운 토론을 지향.
- 코드 구현 시에는 구현되어 있는 코드를 line-by-line으로 뜯어볼 예정.
스터디 진행 후
- 이론과 실습 둘 다 블로그에 내용을 정리.
풀잎 노션
풀잎 스쿨은 기본적으로 노션을 적극적으로 사용해요. (노션의 배경과 이모지를 고르느라 고민 했던게 생각이 나네요…) 아무튼 구성원은 노션에서 질문과 답변을 하고 블로그 포스팅 기록을 공유해요. 이외에도 참고 자료와 커리큘럼도 정리할 수 있어서 매우 유용하게 사용할 수 있습니다~
어텐션 매커니즘 (Attention Mechanism)
seq2seq와 Attention은 어떻게 다르지?
Transformer를 공부하기 위해서는 이 모델의 시초부터 알아야 합니다. 트랜스포머 모델은 어디서 처음 나왔을까요?
바로 Google Brain 연구팀에서 발표한 “Attention Is All You Need”라는 논문에서 처음 등장했습니다. (앞으로 이 논문을 기준으로 글을 작성할 예정입니다. )
논문 제목에서 알 수 있듯이 Transformer 모델은 Attention으로 이루어져 있어요. 그래서 Transformer를 본격적으로 공부하기 전에 Attention Mechanism에 대해서 살펴보려고 해요.
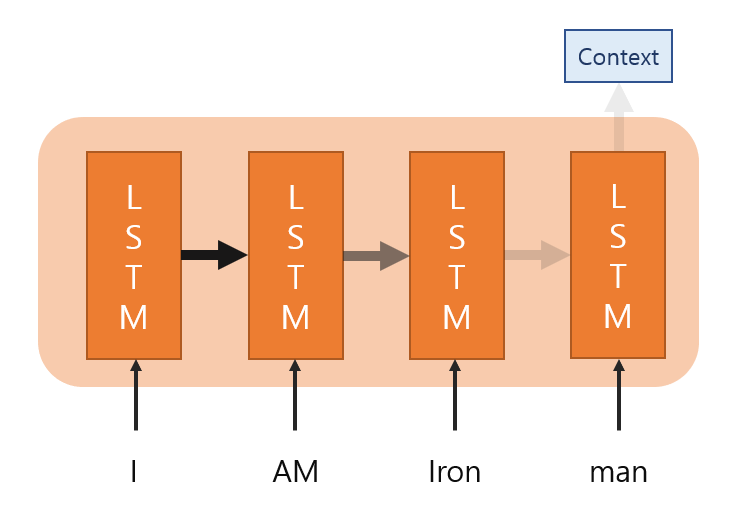
Attention은 기존의 seq2seq의 단점을 해결하기 위해 등장했어요. seq2seq는 번역기에서 사용되는 모델인데, 아주 치명적인 단점을 가지고 있어요.
- 모든 정보를 하나의 context vector에 압축해서 정보 손실이 발생됩니다.
- 모든 LSTM 모델을 거치면서 Gradient Vanishing 문제가 존재합니다.
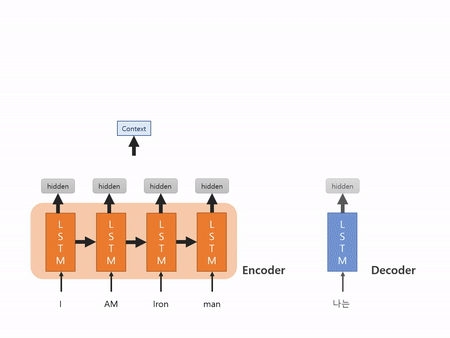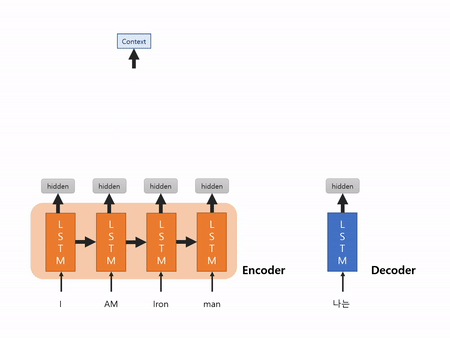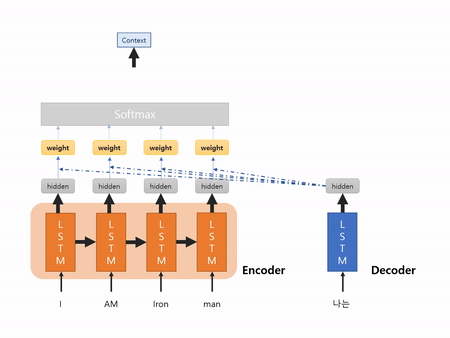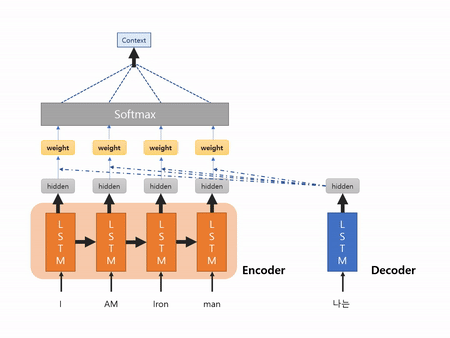
위의 그림을 보면 LSTM 모델을 거치면서 전달되는 정보가 점점 소실되는 걸 보실 수 있을거예요. 또한 Context vect가 고정된 사이즈로 1개가 있기 때문에 문장이 길어져도 고정된 사이즈로 만들어야 해요.
예를 들어서 문장의 길이가 10인 vector를 5로 압축하면 50%의 손실이 발생합니다. 하지만 문장 길이가 100인 vector를 똑같은 size인 5로 압축하면 95%의 손실이 발생하네요.
정보 소실과 기울기 소실, 이 두가지 문제는 모델의 성능에 치명적인 문제를 가져오게 됩니다. 이를 해결하기 위해 Attention 구조가 나오게 되요.
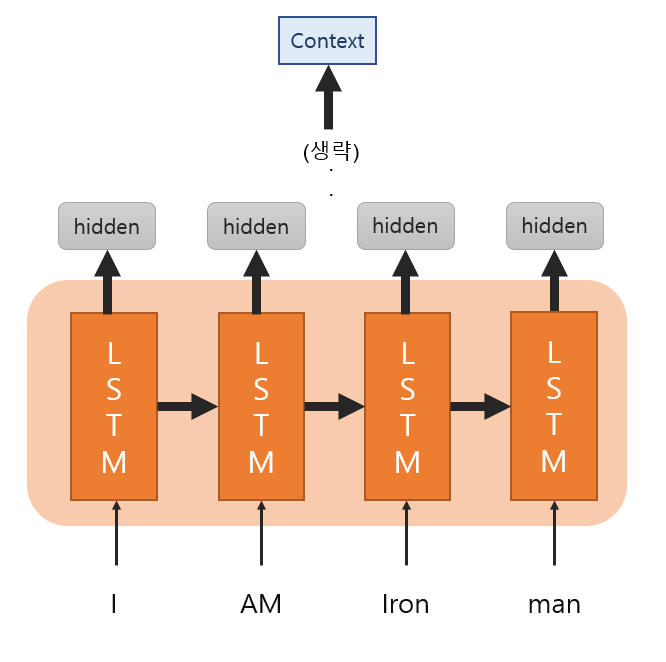
그림 1과는 다르게 Attention 모델은 각 cell의 hidden state를 모두 사용해서 Context vector를 생성해요. 기존의 seq2seq는 한개의 Context vector를 사용해서 크기를 고정하는 반면에, 모든 hidden state 값을 반영하기 때문에 더 유동적으로 사용할 수 있어요!
그런데 그림2에서 생략된 부분이 무엇인지 궁금하실 거예요. LSTM 모델에서 나온 hidden state 값을 단순히 더해서 Context vector가 추출되는 건 아닙니다. 생략된 곳에서는 어떤 일이 일어나는 지 같이 살펴볼게요.
Context vector가 만들어지는 과정
다음 시간
다음 시간에는 본격적으로 “Attention Is All You Need” 논문을 읽을 예정이예요. 천천히 그리고 꼼꼼하게 읽는게 목표이기 때문에 Model Architecture까지를 목표로 잡았습니다!
본격적으로 Transformer를 공부하기 전에 Self-Attention에 대한 이해를 하고 갈 예정입니다. 그리고 논문 구현을 고려하고 있기 때문에 아키텍쳐 부분은 매우 중요할 것 입니다.