hyper-parameter를 자동으로 최적화 해주는 WandB의 Sweep이라는 Tool을 소개하는 글입니다.

![]()
개요
Kaggle이나 Hackathon과 같은 머신러닝 프로젝트를 진행할 때, 우리는 가장 성공적으로 프로젝트를 끝내고 싶을 것 입니다. 이럴때 모델의 성능을 1%라도 높이기 위해서 부단한 노력을 합니다. 그래서 모델을 바꿔보기도 하고, 데이터를 더 추가해서 성능을 높이는 작업을 합니다. 이와 마찬가지로 하이퍼 파라미터를 변경하며 최적의 값을 찾기 위한 실험을 진행합니다. 처음 한 두번은 괜찮지만, 실험이 지속되다 보면 다음 값을 뭘 넣어야 할지도 막막하고, 점점 지치게 됩니다. WandB의 Sweep은 저희의 이런 고달픔에서 벗어날 수 있게 해주는 유용한 Tool입니다. 앞으로 이 Sweep에 대한 소개를 하려고 합니다. 글을 보며 Sweep란 무엇인지 알아보고 Sweep의 사용법을 살펴보겠습니다. 읽기 전에 WandB에 대해서 알고 싶으신 분은 아래 링크를 클릭하시면 됩니다.
Sweep이란?
Sweep은 기본적으로 하이퍼 파라미터를 자동으로 최적화 해주는 도구입니다. Hyper parameter를 사용자가 선택한 method로 최적화를 진행합니다. Sweep에서 제공하는 search 방식은 grid 방식, random 방식, bayes 방식이 있습니다. 선택한 search 방식으로 하이퍼 파라미터 튜닝이 완료 되면 WandB의 웹에서 제공되는 dashboard로 시각화된 모습을 볼 수 있습니다. 이렇게 시각화된 모습은 아래 그림과 같습니다. Sweep은 자동으로 tuning해주는 기능 뿐만 아니라, 각각의 hyper parameter들이 metric(accuracy, loss 등)에 얼마나 중요한 지 알려주고 상관관계를 보여줍니다. 이러한 내용은 차차 글을 통해 알아보도록 하겠습니다.
Sweep 사용법
Sweep을 실행하려면 꼭 필요한 2개의 단계가 있습니다. 그래서 2가지 단계를 토대로 순차적으로 설명드리겠습니다.
- Initialize the sweep
- Sweep의 구성요소를 정의하고, 프로젝트에서 사용하기 위해 Sweep API로 초기화 하는 부분입니다.
- Run the sweep agent
- 함수 또는 프로그램은 WandB 서버에서 실행 시킵니다.
이 2가지 단계만 실행한다면 Sweep을 사용할 수 있습니다. 이 글에서는 학습 log와 파라미터를 추적할 수 있는 기능은 생략하도록 하겠습니다. 이에 대한 내용은 다음 링크를 통해 알 수 있습니다. 코드를 통해 전체적인 process만 이해하고 싶으신 분들은 Sweep 사용법을 건너 뛰시고 바로 코드 구현을 보시는 것을 추천드립니다!
(1) Initialize the sweep
WandB의 Sweep 도큐먼트를 보시면 친절하게 설명이 나와있습니다. 이 도큐먼트에서 나와있는 설명을 기반으로 글을 작성하도록 하겠습니다.
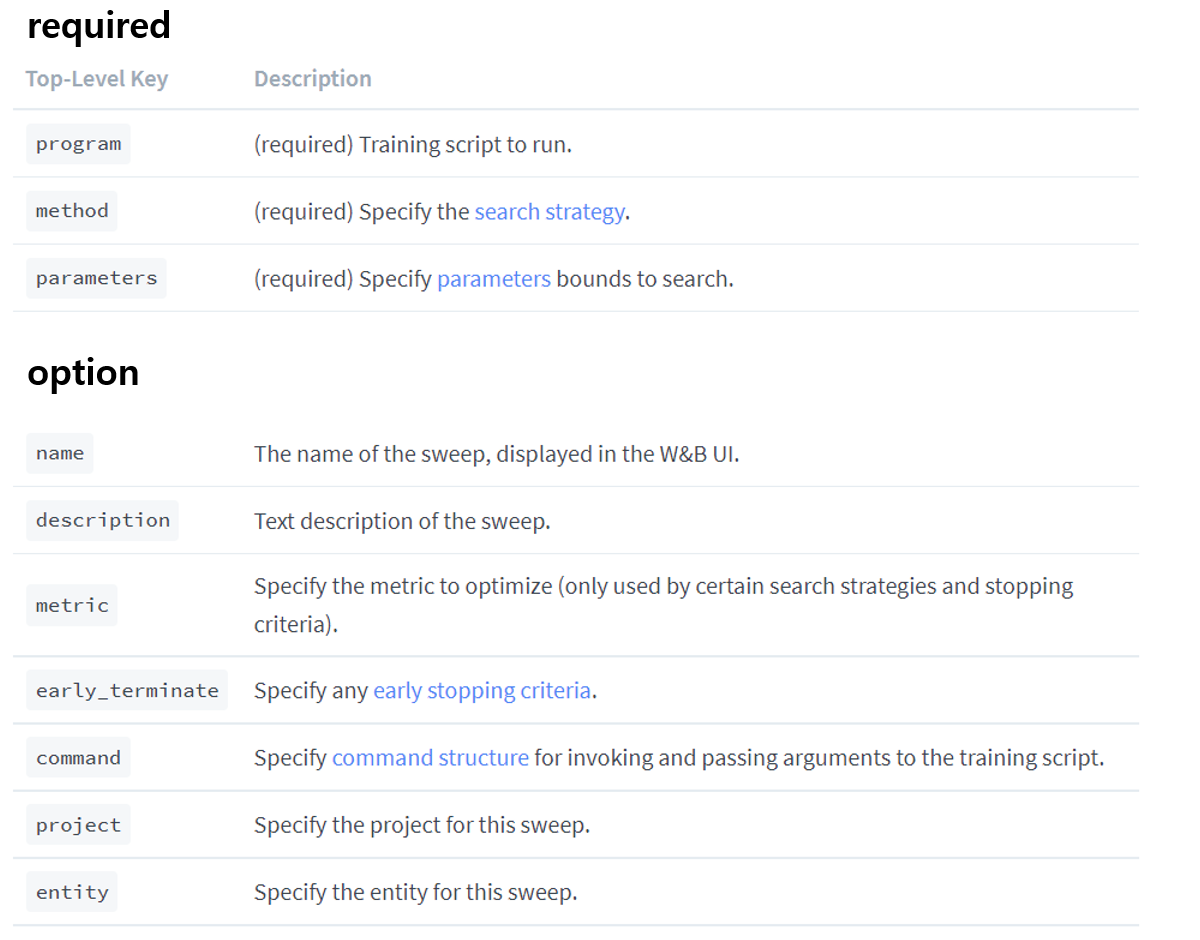
Sweep을 Initialize 하는 파트는 쉽게 말하면 구성요소(Configuration)를 정의하고 프로젝트에 적용한다고 생각하시면 됩니다. Configuration은 위와 같은 구조로 정의되어 있습니다. 즉, 이 기능들만 알고 있다면 Sweep을 편하게 사용하실 수 있습니다.
위의 그림을 보시면 Configuration은 필수 요소(required)와 선택 요소(option)으로 나누어져 있습니다. 먼저 sweep은 하이퍼 파라미터를 최적화해주는 도구이기 때문에 어디(program)에서 무엇(prarameter)을 어떻게(method) 최적화 할 것인지 정의 해줘야합니다. 그래서 required은 꼭 정의 해줘야합니다. method는 grid, random, bayes 방식이 있습니다. “잠깐, grid와 random은 알겠는데 bayes 방식은 뭘까?”라고 생각하시는 분들이 계실 것 입니다. 그래서 bayesian optimization 방식에 대한 설명은 추후에 따로 글을 작성해서 설명드리도록 하겠습니다.
그리고 가장 중요한 parameters 파트를 살펴보겠습니다. 위 그림에서 파란색 글씨로 표시된 parameter 링크를 클릭하시면 자세한 설명을 볼 수 있습니다.

-
values와 value
values와 value는 하이퍼 파라미터의 범위를 설정해줍니다. 특정 값을 설정해서 우리가 원하는 값만 선택하게 해줍니다. 그리고 value는 1가지 값을 설정해줄 때 사용합니다.
-
distribution
이와 대조되는 범위 설정 방식이 바로 distribution입니다. 특정 값을 설정하는 대신 원하는 분포 안에서 값을 선택하게 해줍니다. Sweep에서는 uniform, normal, q_log_uniform과 같이 다양한 분포를 제공해줍니다. 또한 선택된 분포를 min, max와 mu, sigma, q를 통해 자유롭게 변형할 수 있습니다.
-
min, max
min, max는 말 그대로 분포의 최소값과 최대값을 설정해줍니다.
-
mu와 sigma
mu와 sigma는 평균과 표준편차를 나타내는 값으로, 정규분포(normal)의 모양을 결정하는 데 사용됩니다.
-
q
q는 Quantization의 약자로 distribution에서 나온 값 X를 양자화 시킵니다. 예를 들어 q를 2로 설정한다면 X는 2의 배수로 바뀌게 됩니다. (ex. 식 round(X / q) *q를 적용하면, -2.96은 -2로 13.27은 14로 8.43은 8로 바뀌게 됩니다.)
Sweep의 config가 제대로 정의가 됐다면 이제 프로젝트에 적용을 해줘야합니다. sweep을 초기화하는 코드는 다음과 같습니다.
sweep_id = wandb.sweep(config.sweep_config)
위에서 정의된 config 변수를 입력으로 받고 sweep id를 출력해줍니다. 이 id는 다음 step에서 sweep을 실행시킬 때 고유 식별자로 사용이됩니다.
(2) Run the sweep agent
이제 초기화까지 마무리 되었다면 본격적으로 실행시키는 일만 남았습니다. 위에서 정의해준 configuration을 사용해서 Sweep을 해줍니다. 코드는 다음과 같습니다.
wandb.agent(sweep_id, function=my_train_func, count=count)
위에서 wandb.sweep을 통해 생성된 id를 입력으로 넣어줍니다. 또한 우리가 정의한 train 함수를 넣어주고 몇번 sweep을 진행할 지 숫자를 입력해줍니다. 다음과 같은 실행화면이 보인다면 성공적으로 Sweep을 실행시킨 것입니다.
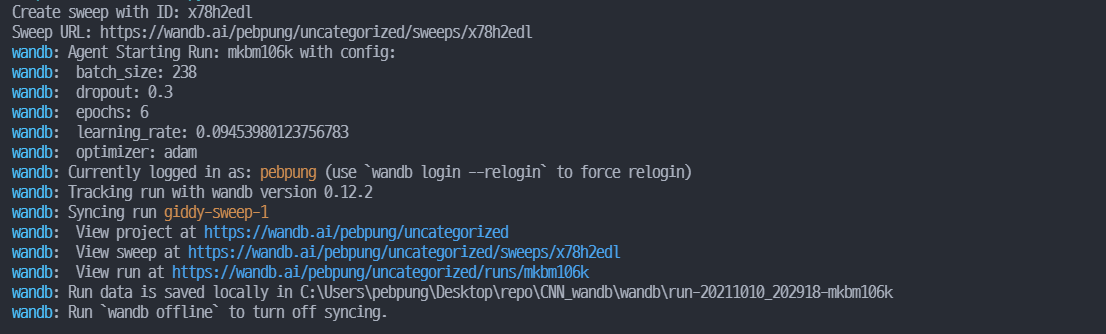
entity와 project도 agent 에서 입력할 수 있습니다. 하지만 저 같은 경우 config 파일에서 기입해줬기 때문에 굳이 적어줄 필요가 없습니다. 이 외에도 entity, project를 설정해주는 곳이 다양합니다.
Project와 entity를 기입 가능한 곳
-
config 설정 하는 파일 (config.py 혹은 config.yaml)
-
wandb.sweep()
-
wandb.init()
-
wandb.agent()
(3) Yaml 파일로 실행하는 법
configration은 파이썬 파일(*.py)로 정의하는 방식과 YAML 파일(*.yaml)로 정의하는 방식이 있습니다. 이번 글에서는 파이썬 파일로 실행시키는 방식을 기준으로 설명드렸습니다. 그래서 yaml 파일로는 어떻게 실행시키는 지 추가적으로 설명드리겠습니다.
-
yaml 파일을 생성합니다.
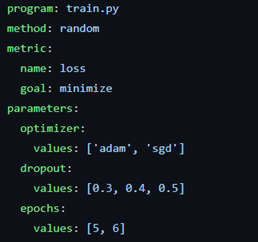
-
yaml 파일을 sweep에 입력합니다.
wandb sweep YAML_FILE
-
Sweep id를 agent에 입력합니다.
wandb agent SWEEP_ID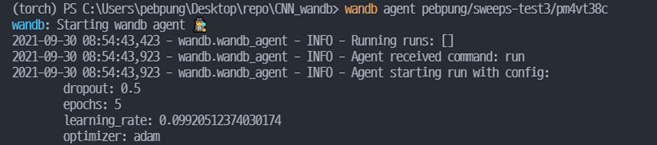
코드 구현
from dataset import SweepDataset
from model import ConvNet
from optimize import build_optimizer
from utils import train_epoch
import wandb
import config
def train():
wandb.init(config=config.hyperparameter_defaults)
w_config = wandb.config
loader = SweepDataset(w_config.batch_size, config.train_transform)
model = ConvNet(w_config.fc_layer_size, w_config.dropout).to(config.DEVICE)
optimizer = build_optimizer(model, w_config.optimizer, w_config.learning_rate)
wandb.watch(model, log='all')
for epoch in range(w_config.epochs):
avg_loss = train_epoch(model, loader, optimizer, wandb)
print(f"TRAIN: EPOCH {epoch + 1:04d} / {w_config.epochs:04d} | Epoch LOSS {avg_loss:.4f}")
wandb.log({'Epoch': epoch, "loss": avg_loss, "epoch": epoch})
sweep_id = wandb.sweep(config.sweep_config)
wandb.agent(sweep_id, train, count=2)
위는 wandb의 sweep을 실행 시키기 위한 전체 코드입니다. sweep을 위한 config 파일은 config.py에 구현되어 있습니다. 코드를 순서대로 설명하면 다음과 같습니다.
- hyper parameter의 초기값을 wandb.init에 입력으로 넣어줍니다.
- w_config는 sweep을 할 대상 hyper parameter입니다.
- loader, model, optimizer 함수에 w_config를 매개변수로 전달해줍니다.
- model을 정의하면 wandb.watch 함수로 gradient를 추적합니다.
- epoch 별로 나오는 log를 wandb.log에 저장합니다.
- config 파일에 정의해둔 구성 요소를 wandb.sweep에 입력합니다.
- wandb.sweep에서 나온 id와 위에 구현된 train 함수, 그리고 횟수를 wandb.agent에 입력하고 sweep을 실행시킵니다.
전체 코드는 아래 링크를 통해 보실 수 있습니다.
Sweep 시각화
Sweep을 실행시켰다면 이제 시각화된 결과를 분석하는 일만 남았습니다. 체계적으로 분석하기 위해선 Sweep workspace가 어떻게 구성되어 있는지 알아야합니다. workspace의 구조를 하나하나씩 뜯어보도록 하겠습니다.
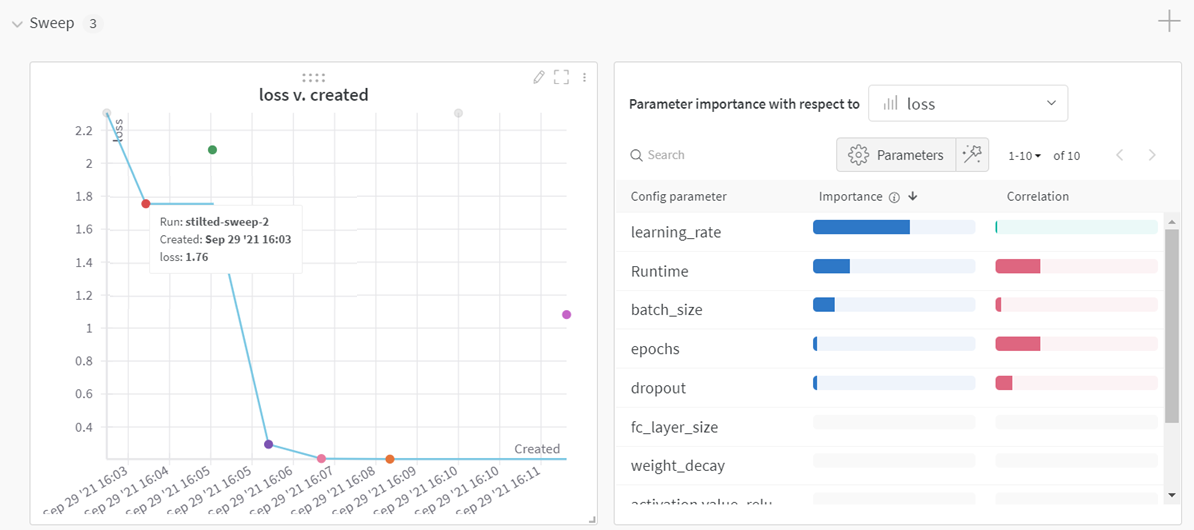
먼저 왼쪽의 그래프에서 X축은 metric, Y축은 생성된 날짜를 보여줍니다. 그리고 오른쪽 표는 hyper parameter가 metric(accuracy, loss 등)에 얼마나 중요한 지와 상관관계가 어느정도 인지도 알려줍니다. 예를 들어, learning rate는 중요도는 높지만, loss와 상관관계는 없어보입니다.
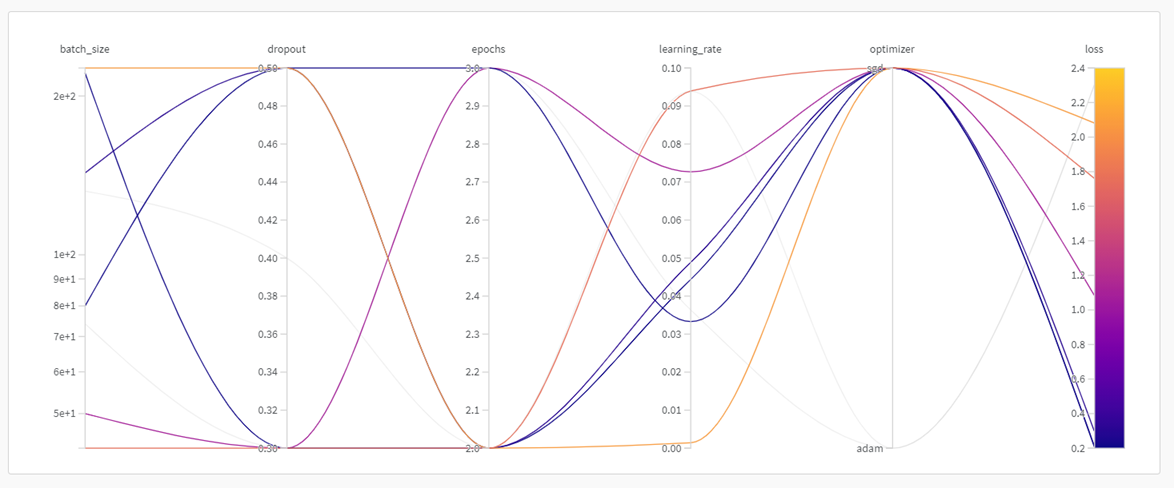
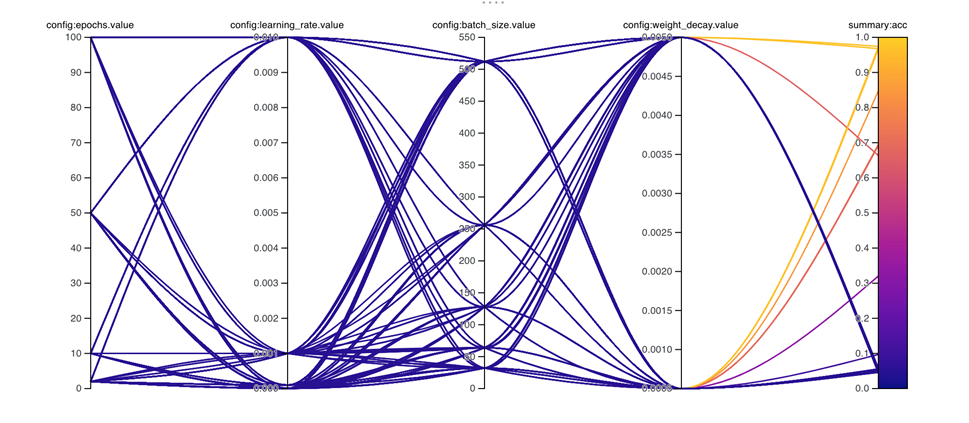
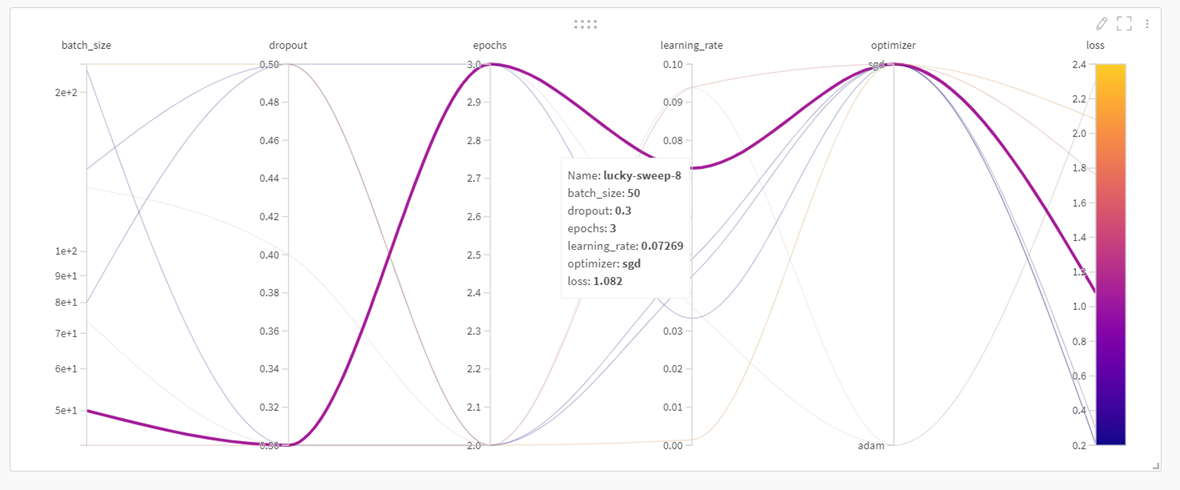
위의 그림은 hyper parameter 선택 과정을 시각적으로 보여준 그림입니다. X축은 config에서 설정한 hyper parameter의 종류를 보여줍니다. 그리고 Y축의 경우 config에서 설정한 hyper parameter의 범위를 보여줍니다. 마우스를 가져가면 해당 그래프의 값을 확인할 수 있습니다.
결론
이번 글에서는 hyper parameter를 자동으로 바꾸며 실험해주는 Sweep에 대해서 알아보았습니다. WandB의 도큐먼트의 경우 한글 버전과 영어 버전이 있습니다. WandB는 지금도 계속해서 업그레이드 중이기 때문에 영어 버전으로 봐야 더 많은 기능을 볼 수 있습니다.
Sweep에서 hyper parameter를 튜닝하는 방법이 대표적으로 3가지 방식이 있었습니다. 다음 글에서는 grid, random search 방식을 간단하게 살펴보고 baysian optimization 방식으로 하이퍼 파라미터를 tuning하는 방식을 자세하게 보겠습니다. 추가적으로 세가지 방식으로 각각 실험을 진행하여 성능이 얼마나 차이가 있는 지 알아보겠습니다.