Summary:
OPLS stack: OpenAI, Pinecone, Lanchain, Streamlit 활용한 문서 기반 챗봇 Assistance입니다.
요즘은 LLM의 전성시대라고 과언이 아닐 만큼 대규모 언어 모델이 쏟아져 나오고 있습니다. 특히 GPT-4가 공개된 이후에는 일반 사용자뿐만 아니라, 기업에서도 이를 적용하겠다고 줄을 잇고 있습니다. 그만큼 AI에 대한 관심도와 ChatGPT를 이용한 서비스에 관심이 커지고 있습니다.
그래서 이번 포스팅에서는 OpenAI, Pinecone, LangChain Framework(이하 OPLS stack)를 활용하여 나만의 Chatbot을 만드는 방법을 알려드리고자 합니다. ChatGPT는 일반적인 질문에는 제법 그럴싸한 대답을 하지만, 자세히 살펴보면 아직 한계가 존재합니다. 이 때문에 프롬프트 엔지니어링과 거짓 답변을 판단해야 하는 확인 절차가 필요합니다. 특히나 일반 질문이 아닌, 최신성과 신뢰성이 있어야 하는 전문적인 답변이 필요할 때는 검증 과정이 필수적입니다.
위에서 언급한 OPLS stack으로 ChatGPT에 정보를 제공할 수 있다면, 이전보다 훨씬 신뢰도 높고 최신의 정보를 기반으로 답변을 얻을 수 있을 것입니다. 지금부터 OPLS stack에 대한 자세한 정보과 활용 방법, 그리고 예시 코드까지 차근차근 설명하겠습니다.
목차
- OPLS stack이란?
- OPLS stack 활용 프로젝트 소개
- 마무리
1. OPLS stack이란?
ChatGPT는 이제 없어서는 안 될 서비스 중 하나가 되었습니다. 저도 코딩하거나 문서 작업을 할 때 정말 많은 도움을 받고 있습니다. 하지만 ChatGPT에서 나온 결과물을 그대로 사용하기엔 아직 한계가 존재합니다. 위의 짤과 같이 실제 어려운 코딩을 맡기면 안 돼서 완성해 주지만, 해당 코드를 실제 사용할 수 있는 코드로 바꾸는 과정이 더욱 오래 걸립니다. 이와 같은 문제로 ChatGPT는 인사이트를 주는 도구 이상으로는 사용하지 못하고 있습니다. 특히 다음 두 가지 문제가 가장 큰 숙제라고 생각이 됩니다.
-
ChatGPT 환각(hallucination)
초기 ChatGPT 모델의 경우 실제 정보와 일치하지 않는 응답을 진실처럼 내놓는 현상이 있었습니다. 이를 인공지능의 hallucination 현상이라고 합니다. 물론, OpenAI에서 자체적으로 방어할 수 있는 기술을 탑재했지만, 모든 출력이 사실이라고 단언하기는 힘듭니다. GPT-4를 출시를 통해 더 정확한 답변을 내놓게 됐지만, 이러한 현상을 방지하기 위해선 반드시 답변에 대한 검증이 필요합니다.
-
정보의 한계 (limited knowledge)
두 번째로 가장 널리 알려진 문제는 최신성입니다. ChatGPT는 공식적으로 2021년까지의 정보 (약 2년 전) 정보까지만 제공합니다. 정확하지 않은 정보를 제공하거나, 최신 업데이트 된 정보를 반영하지 못하기 때문에 출력 결과를 그대로 사용하지 못하는 경우가 있습니다.
OPLS stack을 활용하면 GPT에게 정보를 추가로 제공하여 문제를 해결할 수 있습니다. LLM(대규모 언어모델) 위에 Vector Stores(정보 저장소)를 추가하고 Langchain이라는 프레임워크를 사용하여 전체 프로세스를 구축하는 방식입니다. 각 Framework에 대한 설명을 간략하게 하면 아래와 같습니다.

OpenAI
ChatGPT를 개발한 기업으로 잘 알려진 OpenAI는 GPT-3.5와 GPT-4을 포한한 고성능의 챗봇 모델를 제공합니다. 또한 텍스트를 임베딩으로 변환하는 임베딩 모델도 제공합니다. (생각보다 사용방법이 간단해서 놀랐습니다.) 물론 Bard와 LLaMA와 같은 chatbot LLM이 존재하지만, 이번 포스팅에서는 OpenAI만을 다룰 예정입니다.
Pinecone
Pinecone은 임베딩 벡터 저장, Similarity 비교 및 빠른 검색 기능을 제공합니다. 아마 구글에 Pinecone을 검색하면 솔방울만 나올겁니다. 그만큼 아직 잘 알려진 프레임워크는 아니지만, 사용법이 간단하고 무료로 사용할 수 있는 Vector Stores 프레임워크입니다.
LangChain
LangChain은 Models, Prompts, Memory, Indexes, Chains, Agents의 총 6개의 모듈로 구성되어 있고, 이 모듈을 결합하여 파이프라인 구조를 만들어줍니다. 올해 초에 공개되었음에도, 다양한 예제와 코드가 공개되어 있어서 발 빠르게 LLM ecosystem을 구축하고 있습니다. LangChain에서는 OpenAI 모델뿐만 아니라, Hugging Face 등의 모델도 사용하는 등 다양한 모델을 수용할 수 있는 확산성까지 가지고 있습니다.
Streamlit
Python으로 Web을 개발하는건 무척이나 어렵습니다. 그러나 Streamlit은 파이썬의 한계를 극복하고 웹 애플리케이션을 만들 수 있는 Powerful 한 프레임워크입니다. 데이터 분석 혹은 딥러닝 모델 등을 만들 때 데이터를 시각화하여 보기 쉽게 만들거나, 간단한 웹 페이지 데모 사이트를 개발할 수 있습니다.
2. OPLS stack 프로젝트 소개
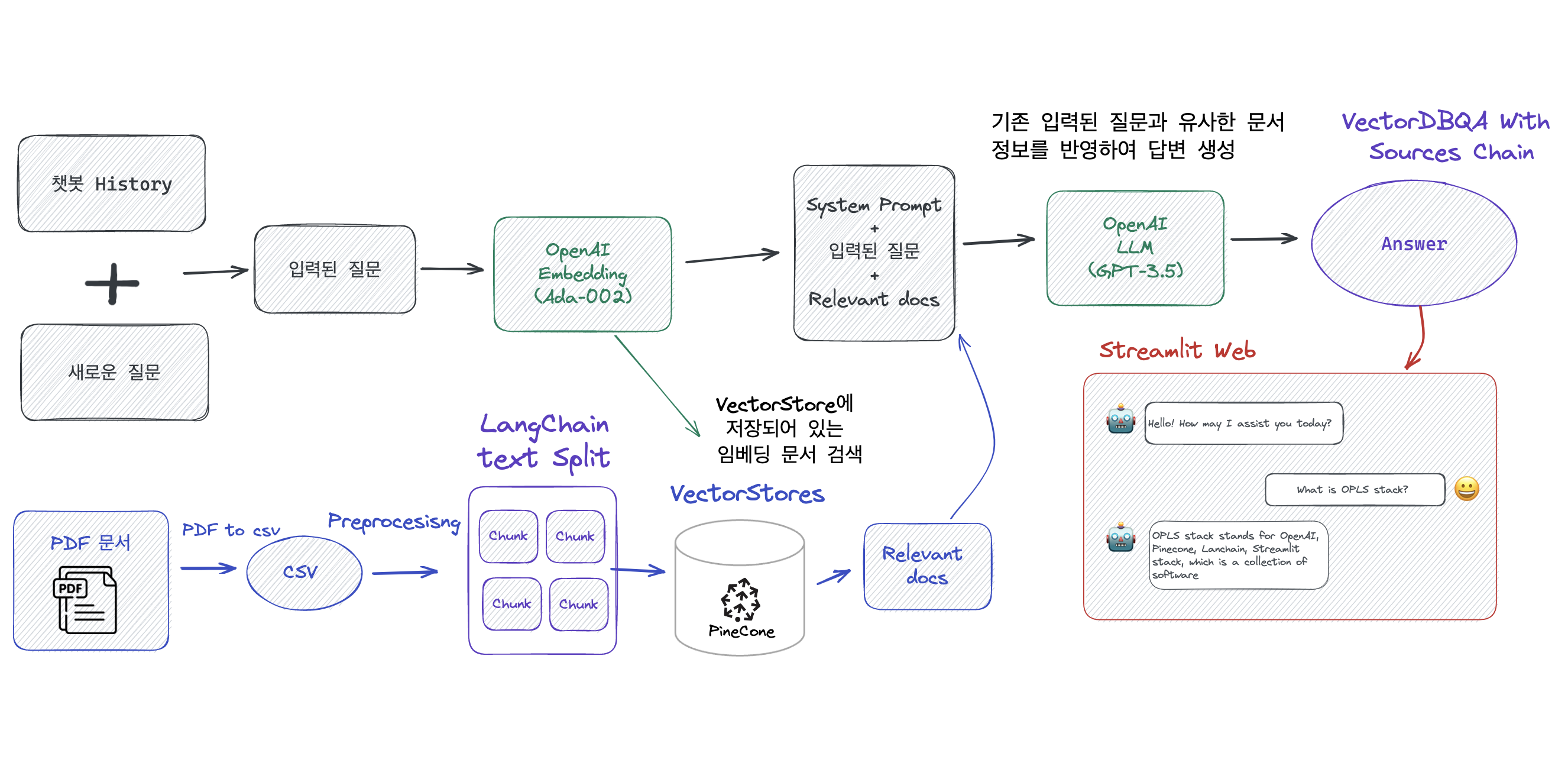
OPLS stack을 활용하여 “원하는 맛집의 정보를 알려주는 챗봇”을 만들 예정입니다. 위의 그림은 챗봇의 개략도를 나타낸 그림입니다.
PDF을 임베딩으로 변환
- PyPDF를 사용하여 PDF를 텍스트로 변환합니다.
- LangChain을 사용하여 텍스트를 청크로 분할합니다.
- OpenAI Embedding Ada-002를 사용하여 텍스트 청크 임베딩을 생성합니다.
- Pinecone을 사용하여 임베딩을 벡터 데이터베이스에 저장합니다.
질문 입력 및 답변 생성
- 사용자의 질문과 history 채팅 context를 받습니다.
- 질문과 context를 처리하여 OpenAI Embedding Ada-002를 사용하여 임베딩을 생성합니다.
- Pinecone에 미리 저장되어 있는 데이터베이스에서 N개의 가장 유사한 임베딩을 검색합니다.
- 입력된 질문과 유사한 임베딩 벡터를 결합하여 OpenAI GPT-3.5에 입력합니다.
- 관련 문서와 질문을 결합한 최종 답변을 Streamlit을 사용하여 시각화합니다.
데이터 구조
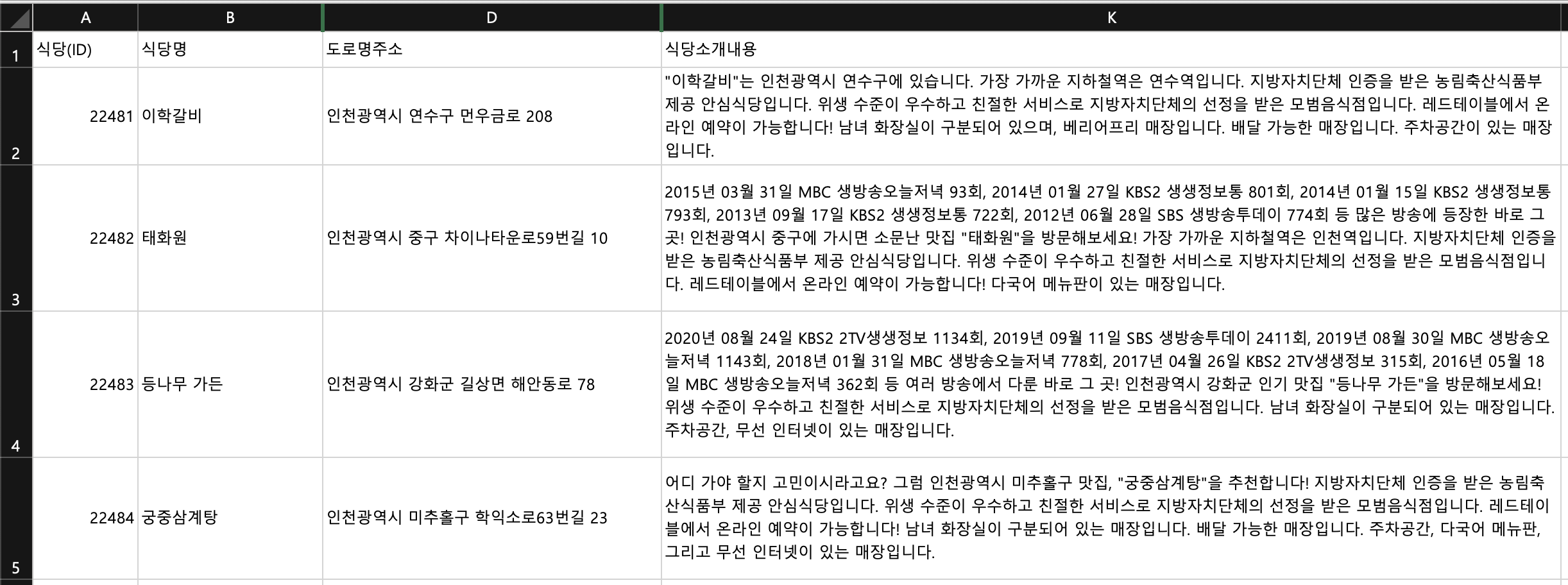
위의 데이터는 공공 데이터 포털에서 다운로드 받은 “인천관광공사 맛집 메뉴설명정보(다국어)” 데이터셋입니다. 해당 데이터에는 식당명, 도로명 주소, 식당 소개, 식당 위치 등이 포함되어 있습니다. 식당 소개 내용을 Pinecone을 활용하여 벡터 스토어에 저장 후에 Top 5의 식당을 사용자에게 추천해줄 예정입니다.
3. 마무리
이번 포스팅에서는 ChatGPT의 한계와 이를 커버하기 위한 OPLS stack에 대해서 알아보았습니다. OpenAI, Pinecone, Lanchain, Streamlit을 적절하게 활용한다면 저희가 원하는 프로덕트를 손쉽게 만들 수 있을 것입니다. 다음 포스트에서는 실제 프로젝트를 구현하는 과정을 코드와 함께 설명드리겠습니다. 코드를 차근차근 따라하면 누구든 자신의 챗봇을 만들 수 있을 것 입니다.