Summary:
-
다양한 LLM 파인튜닝 지원: 100개 이상의 모델과 더불어 LoRA, QLoRA 등 메모리 효율적 기법을 적용할 수 있음
-
입문자 친화적 환경: CLI/웹 UI 제공, 코드 없이도 쉬운 학습 Config 설정과 모니터링 가능
-
최신 최적화 Tool 사용: FlashAttention-2, Unsloth, vLLM 등을 통해 학습/추론 속도 및 자원 효율성 극대화
최근 LLaMA, Mistral, Gemma, Qwen 등 너 나 할 것 없이 자기 모델이 최고라며 성능 좋은 오픈소스 LLM 모델이 쏟아져 나오고 있습니다. 허깅페이스의 open_llm_leaderboard에 등재된 오픈소스 LLM 모델만 해도 2025.03 기준 4,576개 존재하는 것을 확인할 수 있습니다.
특히 LLaMA는 Meta가 공개한 LLM으로 모델 weight를 공개했으며, OpenAI의 ChatGPT와 달리 모델 가중치를 제공하며 상업적 사용도 가능합니다. 이렇듯 Meta가 오픈소스 LLM 진영에 LLaMA를 공개하므로써 오픈소스 LLM 모델의 연구는 더더욱 활발해 지고 있습니다. 그렇게 되면 현존하는 모델보다 더 좋고 빠른 모델이 수도 없이 등장하지 않을까요?
그래서 이번 포스팅에서는 100개 이상의 언어 모델을 위한 통합 효율적 파인 튜닝 프레임워크인 LLaMA-Factory를 소개드리려고 합니다. LLaMA-Factory의 특징을 설명하면서 왜 LLaMA-Factory가 사용하기 편하고, 얼마나 다양한 학습 방법을 지원하는지 살펴보려고 합니다.
LLaMA-Factory 개요
LLaMA-Factory는 베이항 대학교의 연구진이 개발한 오픈소스 프로젝트로, 제한된 컴퓨팅 자원으로도 100개 이상의 최신 LLM 모델을 쉽게 파인튜닝할 수 있도록 설계되었습니다. 웹 기반 인터페이스(LLaMA Board)와 CLI 명령어를 통해 복잡한 코딩 지식 없이도 강력한 LLM을 맞춤형으로 조정할 수 있습니다.
LLaMA-Factory GitHub [링크]
설치 방법
기본 설치
# 저장소 클론
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 설치 (필수)
pip install -e ".[torch,metrics]"
가상 환경 설정 (uv 사용)
uv를 이용한 Python 환경 생성
uv sync --extra torch --extra metrics --prerelease=allow
가상 환경에서 LLaMA-Factory 실행
source .venv/bin/activate
uv run --prerelease=allow llamafactory-cli train examples/train_lora/llama3_lora_pretrain.yaml
가상 환경 설정 v2 (uv 사용)
위 방식으로는 가상환경 세팅이 되지 않아서 아래와 같이 진행했습니다.
uv를 이용한 Python 환경 생성
uv venv --python 3.10 --prompt llamafactory .venv
uv pip install -r requirements.txt
uv pip install -e ".[torch,metrics]"
가상 환경에서 LLaMA-Factory 실행
source .venv/bin/activate
llamafactory-cli train examples/train_lora/llama3_lora_pretrain.yaml
하드웨어 요구 사항
LLaMA-Factory는 다양한 하드웨어 환경에서 작동하도록 설계되었습니다. 파인튜닝 방법에 따른 대략적인 GPU 메모리 요구 사항은 다음과 같습니다.
| 방법 | 비트 | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
전체 파인튜닝 (bf16 또는 fp16) |
32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
전체 파인튜닝 (pure_bf16) |
16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
이를 통해 저사양 GPU에서도 QLoRA와 같은 방법을 활용하면 LLM을 Fine-tuning 할 수 있습니다.
데이터 준비
LLaMA-Factory에서 사용할 데이터는 몇 가지 형식으로 준비할 수 있습니다:
- 내장 데이터셋: 50개 이상의 다양한 데이터셋을 바로 활용 가능
- Hugging Face / ModelScope / Modelers 허브의 데이터셋: 온라인 데이터셋 활용
- 로컬 데이터셋: 자체 데이터를 JSON 형식으로 준비
데이터셋 형식 (JSON)
{
"instruction": "다음 질문에 답변해주세요",
"input": "인공지능이란 무엇인가요?",
"output": "인공지능은 인간의 학습능력, 추론능력, 지각능력을 인공적으로 구현한 컴퓨터 시스템을 말합니다.",
"history": []
}
instruction: 모델에게 주는 지시사항input: 추가 입력 (비워둘 수 있음)output: 기대하는 모델의 출력history: 대화 기록 (비워둘 수 있음)
사용자 지정 데이터셋을 사용하려면 data/dataset_info.json 파일을 업데이트하세요.
빠른 시작 가이드
LLaMA-Factory는 CLI와 웹 UI 두 가지 방식으로 사용할 수 있습니다.
CLI 명령어 사용
다음 세 명령어로 Llama3-8B-Instruct 모델의 LoRA 파인튜닝, 추론, 병합을 수행할 수 있습니다:
# 파인튜닝
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
# 추론 (채팅)
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
# 모델 병합
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
도움말:
llamafactory-cli help명령어로 도움말을 확인할 수 있습니다.
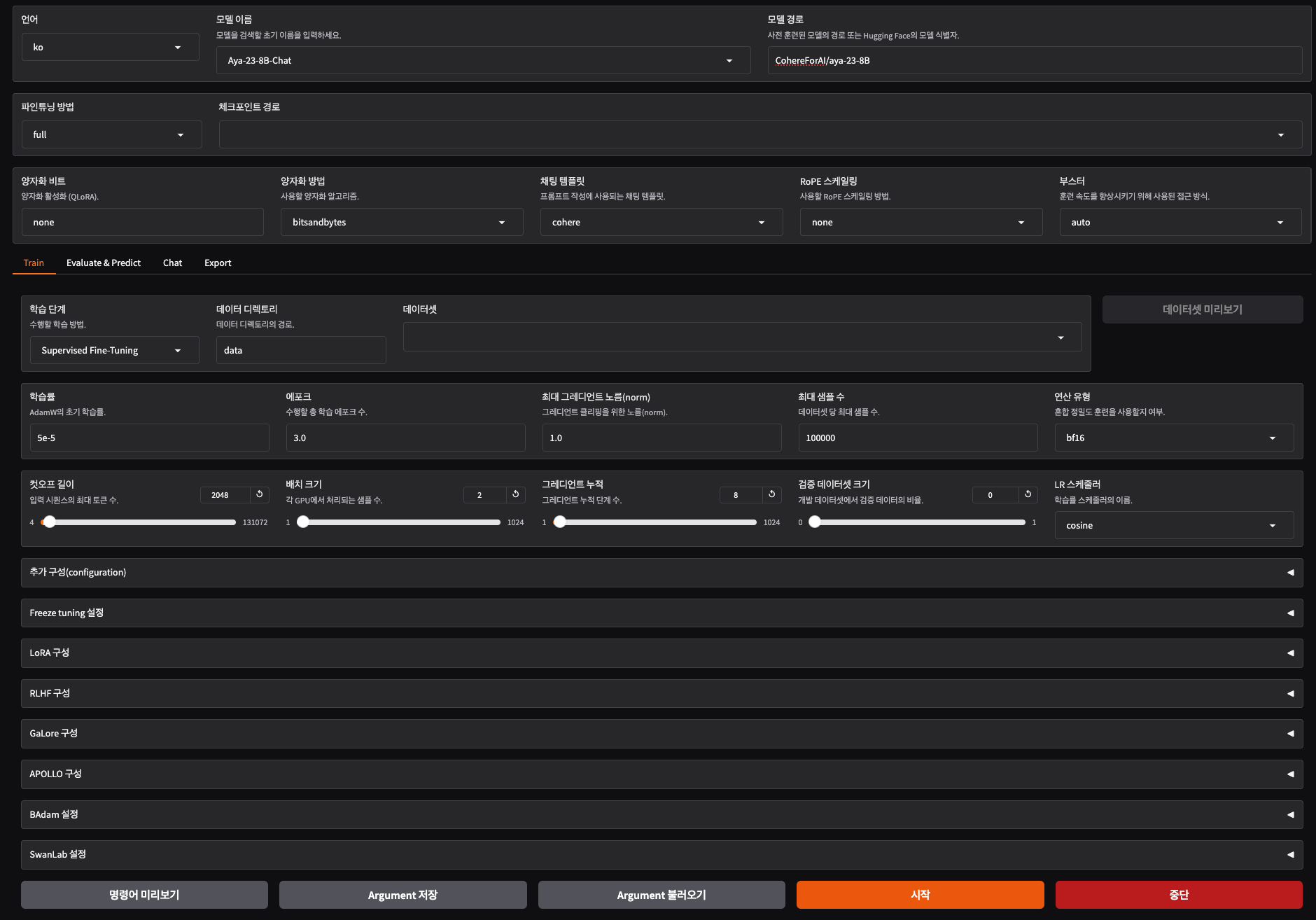
웹 UI 사용 (LLaMA Board)
LLaMA Board는 파인튜닝, 평가, 추론을 위한 직관적인 웹 인터페이스를 제공합니다:
llamafactory-cli webui
웹 브라우저에서 표시된 주소(기본 http://localhost:7860)로 접속하면 다음 기능을 사용할 수 있습니다:
- 학습 구성 탭: 모델 선택 및 기본 설정
- 모델 이름, 어댑터 경로, 파인튜닝 방법, 체크포인트 등
- 학습 탭: 학습 관련 세부 설정
- 학습 단계, 데이터셋 선택, 하이퍼파라미터 등
-
평가 탭: 파인튜닝된 모델 평가
-
채팅 탭: 파인튜닝된 모델과 대화 테스트
- 내보내기 탭: 학습된 모델 내보내기
웹 UI 사용 방법 소개
다양한 모델 지원
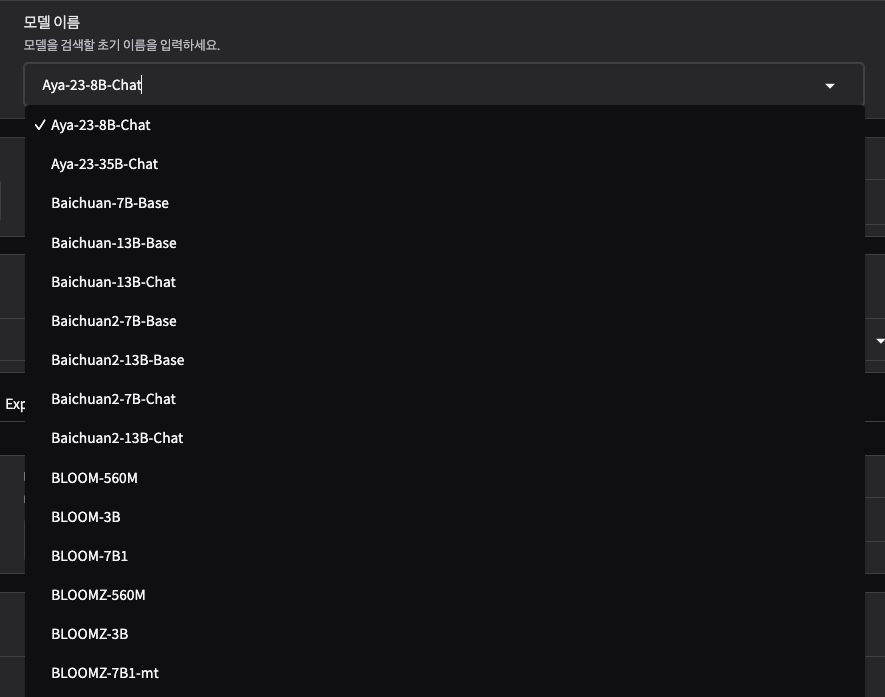
LLaMA-Factory는 정말 많은 모델 학습을 지원하고 있습니다.
위 사진 속 모델들은 일부이며, 스크롤을 내리면 정말 다양한 모델들이 존재하는 것을 확인할 수 있은데요.
LLaMA, LLaVA, Mistral, Mixtral-MoE, Qwen, Yi, Gemma, ChatGLM, Phi 등 100개 이상의 모델 지원합니다. 그 중 DeepSeek, LLaMA 3.3, Qwen 2.5 등 최신 모델 들도 존재합니다.
Fine-tuning 방법 선택 가능
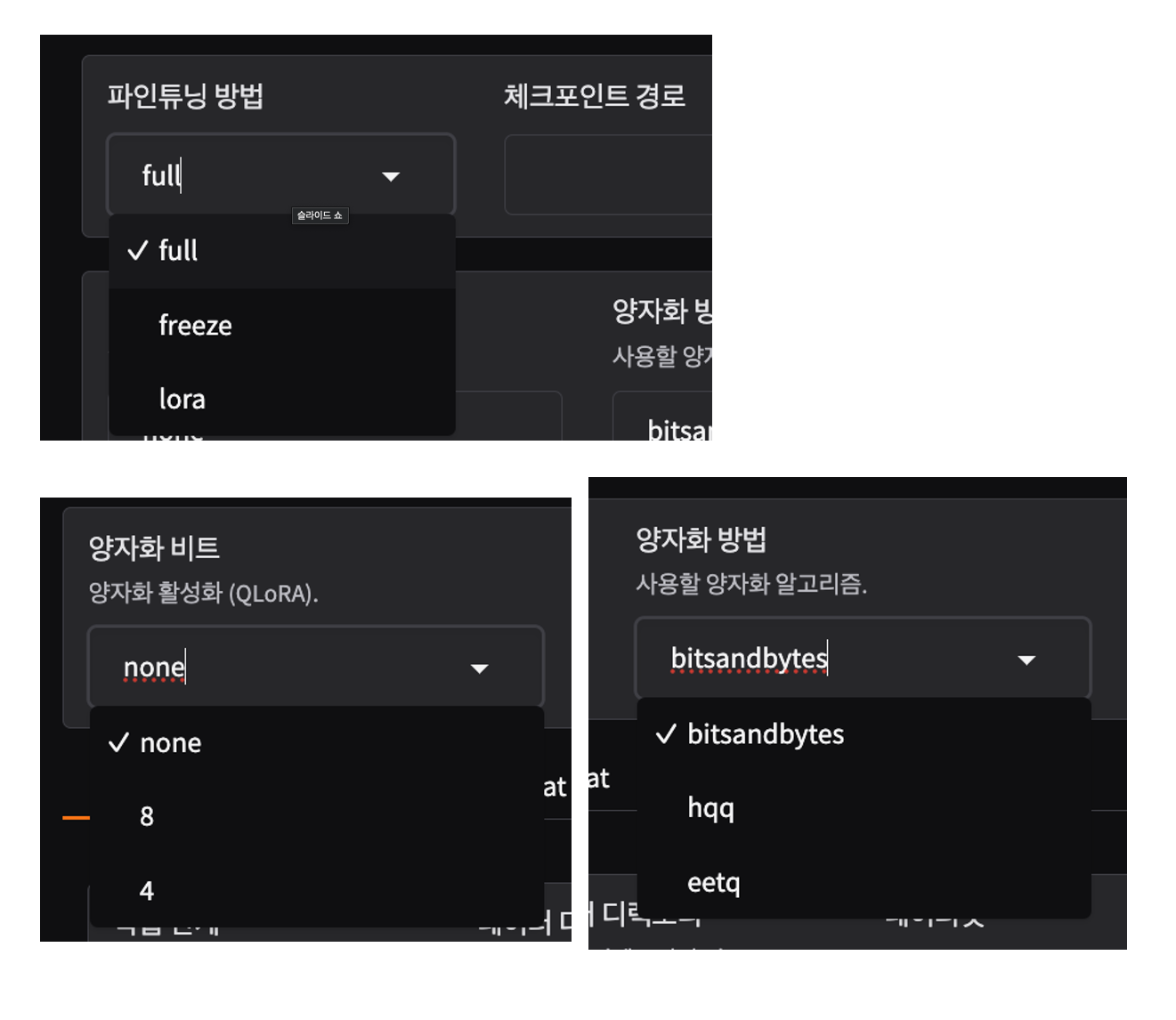
Full Fine-tuning부터 LoRA, QLoRA(2/3/4/5/6/8비트) 등 다양한 메모리 최적화 기법 지원합니다.
1) Full Fine-tuning
모든 모델 파라미터를 업데이트하는 방식으로, 높은 성능을 얻을 수 있지만 많은 memory와 computational resources가 필요합니다.
2) LoRA (Low-Rank Adaptation)
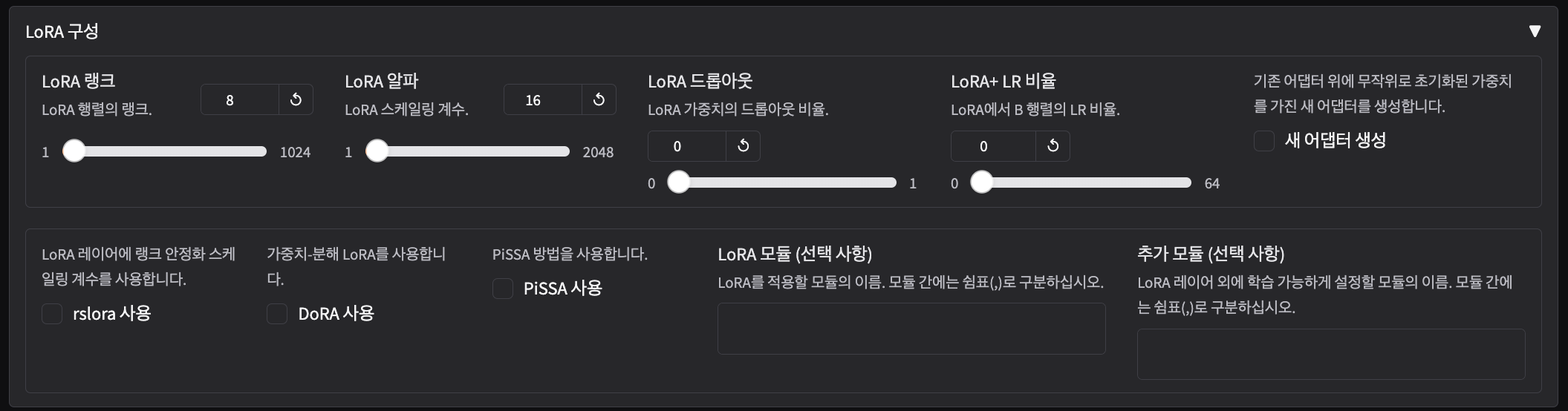
모델의 특정 레이어에 Low-Rank Adaptation를 추가하여 파라미터 수를 크게 줄이는 방법입니다. 메모리 효율적이면서도 꽤 좋은 성능을 제공합니다.
3) QLoRA (Quantized LoRA)
모델을 양자화하여 메모리 사용량을 더욱 줄인 LoRA 방식입니다. 4비트나 8비트 양자화를 통해 일반 GPU에서도 LLM을 Fine-tuning할 수 있습니다.
4) Advanced Fine-tuning 방법
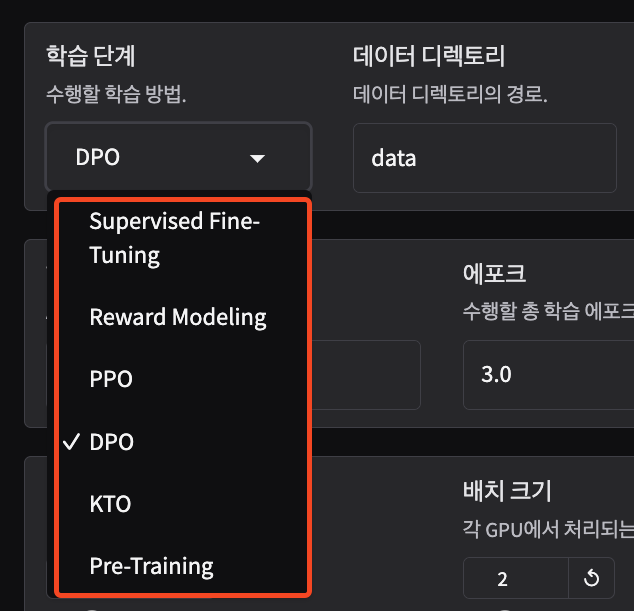
- DPO (Direct Preference Optimization): 선호도 학습을 통한 모델 최적화
- PPO (Proximal Policy Optimization): 강화학습 기반 최적화

- GaLore (Gradient Low Rank Projection): LoRA보다 뛰어난 메모리 효율성과 성능을 동시에 달성하는 LLM 모델 학습 전략
-
DoRA (Weight-Decomposed Low-Rank Adaptation): 가중치 분해 기반 LoRA
- BAdam: Full Fine-tuning 시 메모리를 효율적으로 사용할 수 있도록 설계된 optimizer

고급 기능 및 최적화 기법
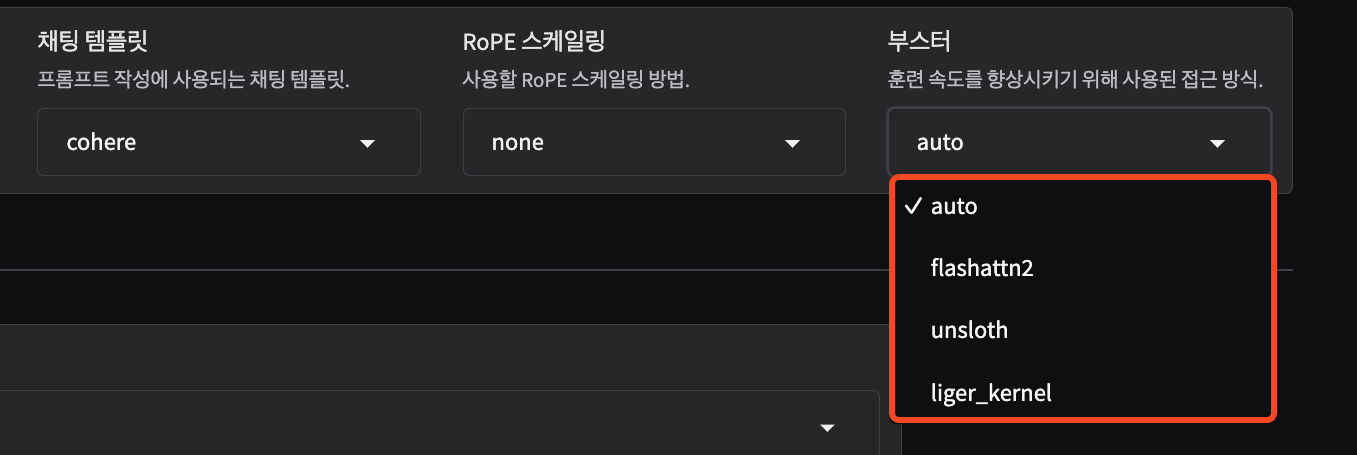
Flash Attention-2
: 대규모 어텐션 연산을 효율적으로 처리하기 위해 설계된 기법
RTX4090, A100, H100 GPU에서 학습 속도를 크게 향상시킬 수 있습니다.
Unsloth
: LLM의 파인튜닝을 최적화하기 위한 툴
Llama, Mistral, Yi 모델에 대해 최대 170% 속도 향상됩니다.
모니터링 도구
웹 UI 사용 시 ‘시작’ 버튼을 클릭하면 학습이 진행됩니다.
학습 과정은 실시간으로 모니터링할 수 있으며, 아래와 같은 Tool을 활용할 수 있습니다.
- LlamaBoard: 내장된 웹 인터페이스를 통한 모니터링
- TensorBoard: 상세한 학습 지표 시각화
- Wandb: 원격 학습 모니터링 및 실험 관리
- SwanLab: 경량 실험 추적 및 시각화
고속 추론
LLaMA-Factory는 vLLM을 통합하여 최대 270%로 추론 속도를 대폭 향상할 수 있습니다.
infer_backend: vllm
또한 SGLang 백엔드도 사용할 수 있습니다.
SGLang은 LLM을 위해 설계된 언어로, 파이썬에 내장된 도메인 특화 언어입니다. 백엔드 런타임 시스템과 프론트엔드 언어를 함께 설계해 LLM과의 상호작용을 더 빠르고 쉽게 제어하는 것을 목표로 합니다.
infer_backend: sglang
결론
라마팩토리를 사용하면서 느꼈던 점은 “처음 사용해본 사람도 별도의 커스텀 없이 사용 가능하다”라는 이점이 와닿았습니다. 실제로 코드 없이 웹 UI/CLI만으로 100개가 넘는 LLM 모델(Llama, Mistral, Qwen 등) 파인튜닝 가능했습니다.
또한 모델/데이터셋/하이퍼파라미터는 YAML 파일로 표준화되어 있어서 버전 관리 및 재현성 보장할 수 있다는 점도 큰 장점이었는데요. 실제 현업에서 LLaMA-Factory를 활용해서 연구 단계부터 production 서비스 배포까지 End-to-End 파이프라인을 구축할 수 있을 것 같았습니다.