Summary
-
Long Context를 효율적으로 처리하는 Long Context Language Models(LCLMs)의 중요성이 커지고 있음
-
LCLM의 성능을 높이기 위해서는 Training 단계에서 고품질의 장문 데이터 확보 전략이 중요함
-
여기서 Data Strategies에는 Data Filtering, Mixture, 그리고 합성 데이터를 생성하는 Synthesis 기술들이 포함됨
-
특히 “lost-in-the-middle” 문제 해결과 Long Context DPO 학습을 위한 데이터 합성 기술이 주목받고 있음
Overview
최근 업무를 하면서 Long Context에서 LLM 성능을 높이는 방법에 대한 필요성을 느끼고 있다.
여러 문서를 입력으로 넣고 쿼리를 날렸을 때 정확한 답변을 받거나, 문서를 깔끔하게 요약해주는 등 방대한 양의 텍스트를 효율적으로 처리하는 능력이 점점 중요해지고 있다.
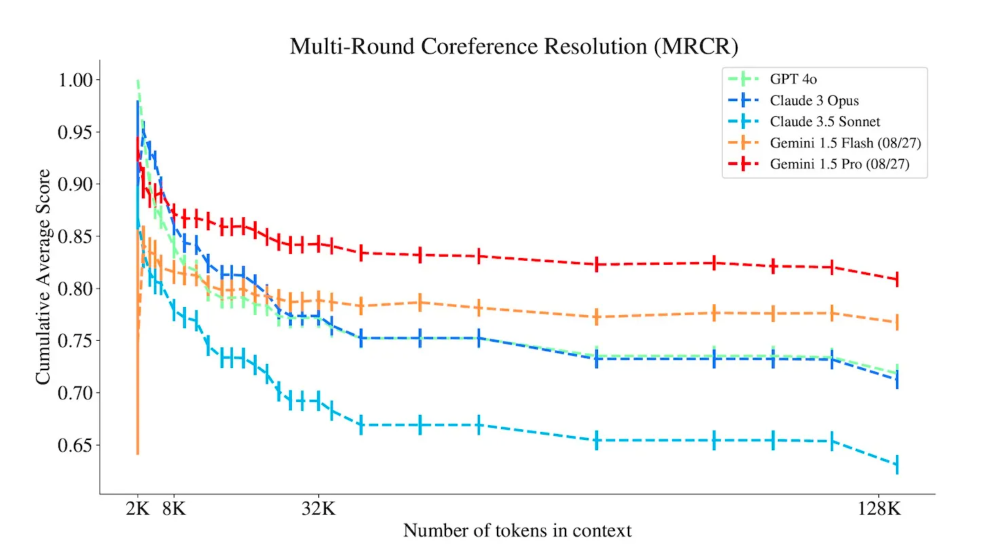
위 그림에서와 같이 Claude, Gemini, GPT와 같은 Closed LLM은 물론이고, Open source LLM에서도 마찬가지로 시퀀스 길이가 늘어날수록 성능 손실이 치명적으로 발생한다.
Qwen2.5-1M처럼 무려 100만 토큰이나 되는 컨텍스트 길이를 처리할 수 있는 모델들이 나오고 있지만, 이런 모델들도 특정 태스크에 맞춰 alignment tuning을 하려면 결국 고품질의 long context 데이터를 확보해야 한다는 과제가 남아있다.
물론 pre-training 단계에서 이미 256k 컨텍스트 길이로 학습되었기 때문에 fine-tuning 효과는 더 좋을 것이다.
그래서 오늘은 “A Comprehensive Survey on Long Context Language Modeling” 논문을 분석해보면서, Pre-training과 Post-training 각 단계에서 어떤 데이터 전략들이 사용되었는지 자세히 살펴보려고 한다.
A Comprehensive Survey on Long Context Language Modeling
Abstract
- 그동안 자연어 처리(NLP) 분야에서 긴 컨텍스트(Long Context)를 효율적으로 처리하는 것은 중요한 과제였음
- 방대한 입력을 효과적으로 분석할 수 있는 긴 컨텍스트 언어 모델(LCLMs)의 필요성이 커지고 있음
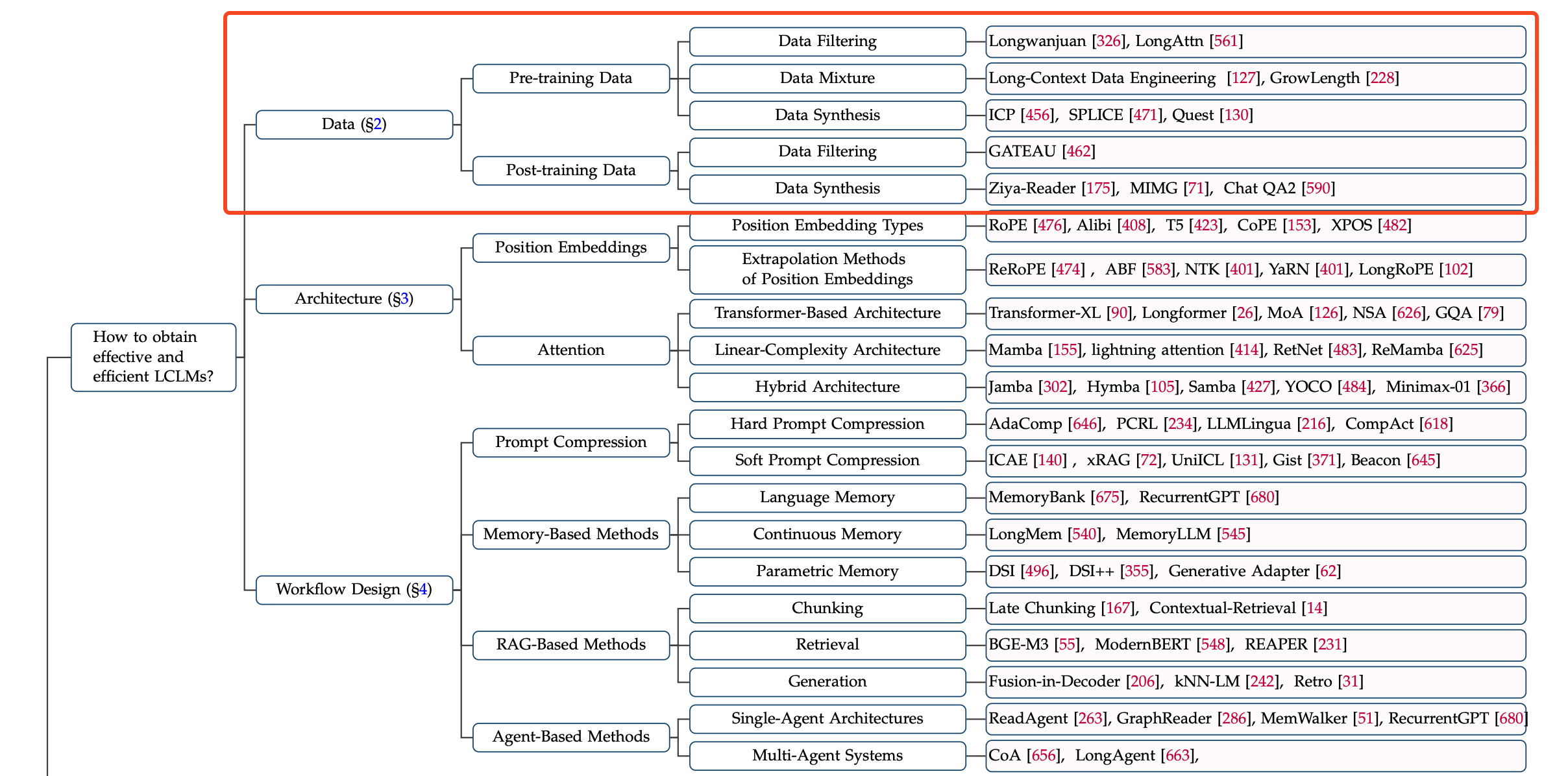
- 그래서 해당 paper에서는 아래의 관점에서 long-context modeling for llm에 대한 종합적인 분석을 수행할 예정임
- 효과적인 LCLM 확보 방안 (how to obtain effective and efficient LCLMs)
- LCLM의 효율적인 학습 및 배포 (how to train and deploy LCLMs efficiently)
- LCLM의 종합적인 평가 및 분석 (how to evaluate and analyze LCLMs comprehensively)
Data Strategies
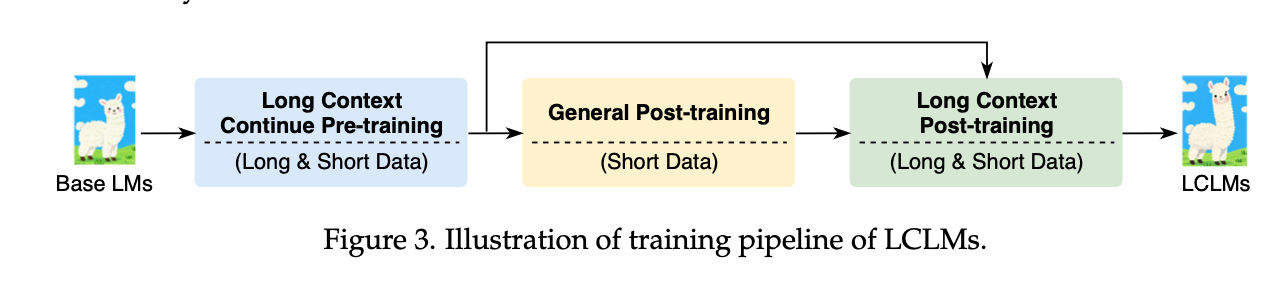
- Pre-training 단계와 Post-training 단계 모두에서 long context 데이터가 사용됨
- 위 figure는 LCLMs의 data processing pipeline을 도식화한 것임
Pre-training
- pre-training에서 중요한 것은 모델의 성능을 극대화하는 것인데, 이를 위해 고품질의 데이터를 확보하고, 이를 효과적으로 혼합하며, 필요에 따라 합성하는 것이 필수적임
- 특히 최근에는 long context 데이터를 정제하는 기술이 급격히 부상하고 있음
1. Data Filtering
- 모델의 성능은 데이터 품질에 크게 의존하므로, 데이터 필터링 기법을 통해 데이터를 정제하는 것이 필수임
- 짧은 텍스트를 제거하는 heuristic한 방식이나 MinHashLSH와 같은 알고리즘을 사용해 중복을 제거하는 기본적인 중복 제거 방법
- SemDeDup와 같이 사전 훈련 모델의 임베딩을 활용하여 의미적 중복을 제거하는 방법이 있음
- 또한, 장문 데이터의 경우 응집성(coherence), 일관성(cohesion), 복잡성(complexity) 같은 언어적 특성을 평가하여 품질을 높이거나,
- LongAttn와 같이 장거리 의존성(long-range dependency)을 기준으로 데이터를 선별하는 기술이 사용됨
2. Data Mixture
- The Pile과 같이 다양한 출처의 데이터를 섞어 사용하는 데이터 혼합 방식은 모델 성능에 직접적인 영향을 미침
- Data Mixing Laws나 RegMix는 data-mixing scaling law을 연구하여 최소한의 비용으로 사전 훈련 효율성을 높이는 최적의 혼합 비율을 찾음
- 소량의 장문 데이터로 continual pre-training을 진행하면 모델의 long information search 능력이 크게 향상될 수 있음
- 특히 컨텍스트 길이를 확장할 때는 pre training 데이터셋의 기존 domain diversity을 유지하면서 긴 시퀀스를 oversampling하는 것이 중요함
3. Data Synthesis
- real-world corpus에서 장문 데이터는 희소하기 때문에, synthesize을 통해 부족한 데이터를 보충해야함
- 클러스터링(clustering) 접근 방식은 의미적으로 유사한 텍스트들을 묶거나, 관련성이 높은 문장들을 결합하는 방식으로 이루어짐
- non-neighboring sentences을 활용한 방식으로 관련성이 있지만 인접하지 않은 문장들을 함께 훈련 예제로 사용하여 문장 표현의 품질을 향상시킴
- ICP는 ‘외판원 문제(TSP)’ 알고리즘을 활용해 문서의 중복성을 해결하며, SPLICE는 유사한 여러 문서를 구조화된 방식으로 묶어 훈련 샘플을 생성함
- Quest는 쿼리 중심의 접근법을 통해 문서들을 그룹화하여 풍부한 문맥을 가진 장문 데이터를 효과적으로 생성함
Post-training
- Post-training 단계에서는 Instruction-following을 강화하기 위해 데이터 처리 방식이 중요함
- 크게 Data Filtering과 Data Synthesis 두 가지 방법이 있으며, 특히 ‘lost-in-the-middle’ 문제를 해결하고, 선호도에 맞춰 모델을 최적화하는 데 (예: DPO) 중점을 두고 있음
1. Data Filtering
- 모델의 Instruction-following 능력을 높이기 위해 영향력 있는(influential) 샘플을 선별
- 최근 GATEAU와 같은 연구에서 Homologous Models’ Guidance와 Contextual Awareness Measurement라는 구성 요소를 도입하여 장거리 의존성(long-range dependency)을 가진 데이터에서 영향력 있는 샘플을 식별하는 방법을 제시
2. Data Synthesis
-
주로 ‘lost-in-the-middle’ 문제를 해결하고, 모델을 선호도(preference)에 맞게 최적화하는 데 활용됨
- Long QA 데이터 합성
- Ziya-Reader는 contexts 내에서 여러 위치를 참고해야 하는 Multi-doc QA를 구축하여 “lost-in-the-middle” 문제를 해결
- pre-training corpus에서 선택한 문서 기반의 질문-답변 쌍을 생성하도록 지시하여 데이터를 생성
- 두 가지 유형의 질문(짧은 구간의 정보를 아주 자세히 파악하거나, 두 개 이상 구간의 정보를 합쳐서 추론)을 포함하는 QA 데이터셋을 합성하여 “lost-in-the-middle” 문제를 해결
- Preference optimization on long context models
- DPO와 같은 선호도 최적화 기법은 주로 short-context 시나리오에만 적용되었지만, 최근에는 long context에 특화된 연구가 진행 중
-
LongReward는 LLM을 활용해 유용성, 논리성 등 인간의 선호도를 기준으로 보상을 제공
-
LOGO는 automatic evaluator로 preference/dispreference 데이터를 합성
- LongDPO는 몬테카를로 트리 서치(Monte Carlo Tree Search)를 통해 단계별 선호도 쌍(stepwise preference pairs)을 수집하여 모델의 장문 생성 능력을 향상시킴
3. Training Data 예시
| Training Data | Characteristics | Stage | Link |
|---|---|---|---|
| LongWanjuan | Bilingual, filtered from SlimPajama and Wanjuan | Pre-training | arxiv, github |
| Long-Data-Collections | A wide variety of data sources | Pre-training | huggingface |
| LongAttn | Long-range dependency selected using attention patterns | Post-training | arxiv, github |
| LongAlign | Diverse tasks and various sources, Self-Instruct | Post-training | arxiv, github, huggingface |
| FILM | Information-Intensive, context length balance, multi-hop reasoning | Post-training | arxiv, github |
| PAM QA | Position-agnostic, multi-hop reasoning | Post-training | arxiv, github |
| LongAlpaca | Self-collected, instruction following | Post-training | arxiv, github, huggingface |
| ChatQA2 | Synthesized from NarrativeQA | Post-training | arxiv, github, huggingface |
| LongMIT | Multi-hop, diverse, automatic | Post-training | arxiv, github, huggingface |
| LongWriter-6k | Long-form generation, output lengths ranging from 2k to 32k word | Post-training | arxiv, github, huggingface |
| Long Reward | Bilingual, preference optimization | Post-training | arxiv, github |
| LOGO | Preference optimization | Post-training | arxiv, github |
| LongDPO | Long-form Generation, preference optimization, step-level | Post-training | arxiv, github |