MLOps를 이해하기 위해선 ML 서비스를 배포하는 데 필요한 역할을 이해하는 것이 중요하다. 이번 챕터에서는 크게 7개의 역할로 나눠서 각자의 역할을 알아보고 원활한 MLOps 환경을 위해서 필요한 능력을 알아보고자 한다.
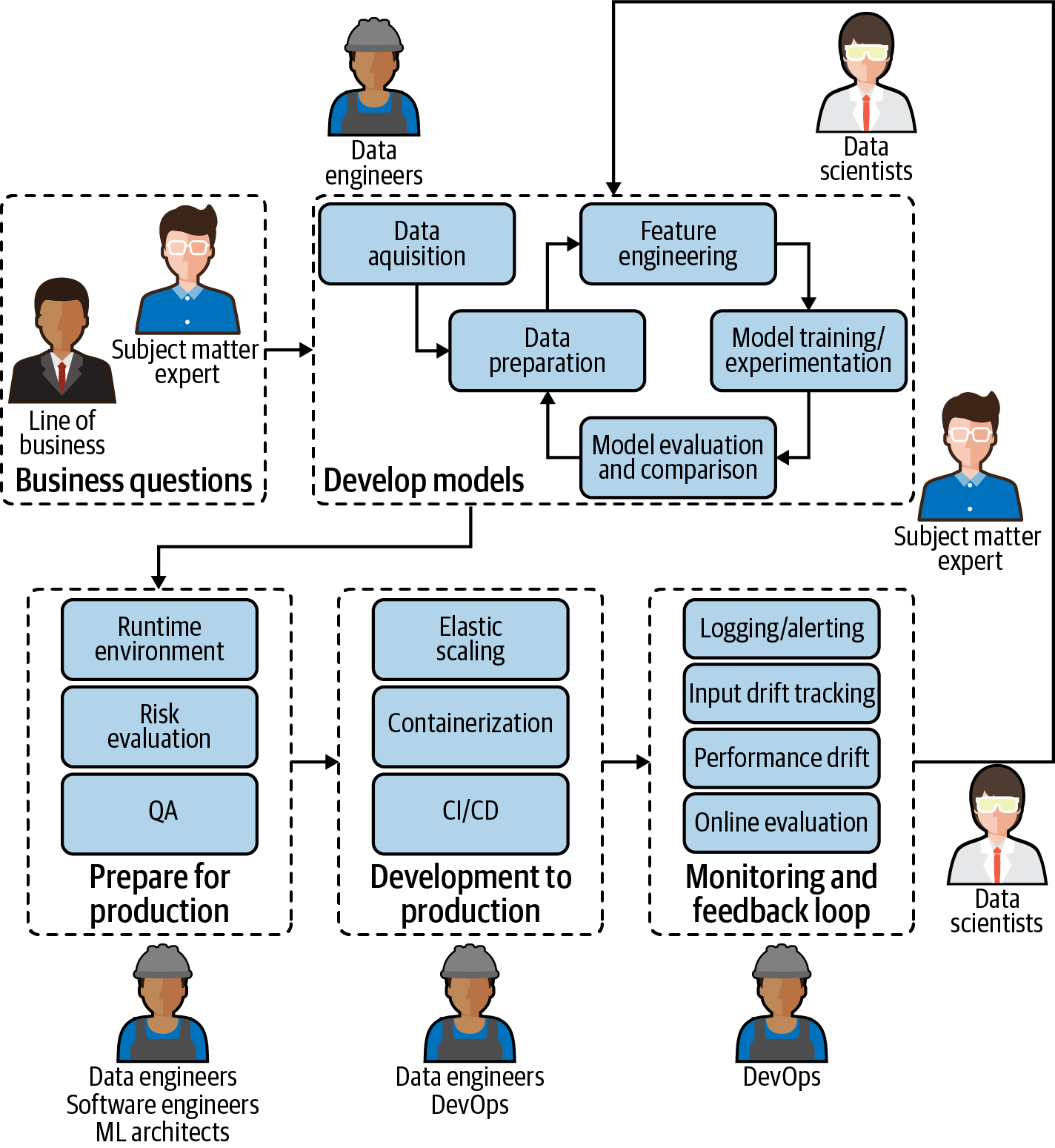
위의 그림은 성공적인 서비스를 배포하기 위해 필요한 역할을 도식화한 그림이다.
Subject matter experts
해당직무 또는 과제를(지식, 기능, 태도 측면에서) 가장 잘 알고, 잘 수행하고 있는 사람을 말한다. ML 서비스에서 SME의 역할은 모델을 구성해야하는 비즈니스 목표 또는 KPI(핵심성과지표)를 제공야한다. 또한 지속적으로 서비스르 평가하고 모델의 성능이 요구 사항과 일치하는지 확인해야된다.
그러나 SME는 머신러닝을 사용하여 해결해야하는 비즈니스 문제에 깊은 이해가 부족한 경향이 있다. 그렇기 때문에 ML 모델 life-cycle에서 SME의 역할을 고려할 때 다음과 같은 사항이 필요하다.
- MLOps 프로세스를 구축할 때 모델의 성능을 비즈니스 관점에서 쉽게 이해할 수 있는 방법을 확보.
- 투명성을 높이기 위해서 데이터 파이프라인을 탐색하고, 어떤 데이터가 사용되는지, 어떻게 개선되는 지 이해.
Data scientists
데이터 과학(data science)이란, 데이터 마이닝(Data Mining)과 유사하게 정형, 비정형 형태를 포함한 다양한 데이터로부터 지식과 인사이트를 추출하는데 과학적 방법론, 프로세스, 알고리즘, 시스템을 동원하는 융합분야다. - 위키백과
이 책에서 데이터 사이언티스트를 위해서는 MLOps가 필요하다고 설명한다. 왜냐하면 데이터 사이언티스트는 사일로[1]된 데이터, 프로세스 및 툴을 다루기 때문에 효과적이지 못하다고 한다. 그럼 이들에게 필요한 역량은 무엇일까? MLOps는 투명성을 강조하고 있기 때문에 다음과 같은 요구 사항을 나열한다.
- 자동화 생산에 빠르고 쉬운 배포를 위한 패키징을 전달.
- 배포된 모델을 지속적으로 개선하기 위한 테스트를 개발하는 능력.
- A/B 테스트 대상 모델 뿐 만 아니라 모든 모델의 성능에 대한 가시성 제공.
- 데이터 파이프 라인을 조사하여 신속하게 평가하고 조정할 수 있는 유연성.
아무래도 ML 서비스에서 모델은 중요한 역할을 차지하고 있으므로 신속하게 평가하고 조정하는 기능을 매우 중요시 여기는 것 같다. 모델을 누가 만들었는지 관계없이 쉽고 안전하게 실제 운영 환경을 구축할 수 있는 패키징을 제공해야된다.
[1] 사일로란 각 부서, 사업 단위나, 브랜치별로 데이터가 일치하지 않는 증상이다.
Data engineers
데이터 엔지니어는 주로 특정 기업에서 데이터를 수집하고 관리하며 유지하는 일을 한다. 데이터 파이프라인은 ML 모델의 핵심이 된다. ‘Garbage in, garbage out’ 이라는 말이 있듯이 데이터를 관리하는 일은 매우 중요하다. 그래서 데이터를 잘 관리할 수만 있다면 좋은 서비스를 배포할 수 있을 것이다. MLOps는 데이터 엔지니어의 역할을 고려하여서 상당히 효율적인 방법을 제시하고 있다.
- 운영 환경에서 구축된 모든 모델의 성능에 대한 가시성 확보.
- 문제가 생겼을 때 해결하기 위해서 데이터 파이프라인의 세부 정보를 볼 수 있는 기능 필요.
Software engineers
소프트웨어 엔지니어는 일반적으로 ML 모델을 제작하진 않는다. 하지만 대부분의 기업은 ML 모델 뿐만 아니라 소프트웨어와 어플리케이션도 생산한다. 결국 ML 모델은 단순한 실험에서 끝나는 것이 아니라, ML 코드, 학습, 테스트는 CI/CD에도 적합해야된다. 소프트웨어 엔지니어는 ML 모델이 다른 어플리케이션과 원활하게 작동하는지 확인해야된다.
- 데이터 직무와 소프트웨어 엔지니어가 동일한 언어를 사용하고 어떻게 운영 환경에서 작동하는 지 이해.
- 버전 관리, 처리 중인 기능 확인, 자동 테스트 기능 등 병렬로 작업할 수 있는 기능 필요.
DevOps
DevOps 팀은 ML 서비스에서 두 가지 주요 역할을 한다. 첫번째로 이들은 ML 모델의 보안, 성능 테스트, 운영 시스템 구축 및 수행하는 역할을 한다. 두번째로 CI/CD 파이프 라인 관리를 담당한다. 두 역할 모두 데이터 직무팀과의 긴밀한 협업을 필요로 한다.
- MLOps를 기업의 대규모 Devops 전략에 맞춰 원할하게 통합.
- 원할한 배포를 위한 파이프 라인 구축.
Model risk managers/auditors
MRM는 프로덕션(실제 환경)에서 ML 서비스에서 발생할 수 있는 리스크를 최소화하는 역할을 맡는다. 서비스가 배포된 뒤 발생하는 리스크는 치명적인 손실을 발생시킬 수 있기 때문에 MRM의 역할이 중요해진다. 그렇기 때문에 프로덕션으로 배포하기 전에 모델의 요구 사항을 모두 충족하는 지 먼저 확인해야 된다.
- MLOps의 요구 사항에 대한 보고서를 작성 할 때 세부 정보, 데이터 정보 등 세밀한 작성 필요.
- 자동화 된 보고 기능을 통해 MRM의 효율성 향상.
Machine learning architects
MLA는 설계에서 개발 및 모니터링에 이르기까지 ML 모델의 확장성과 유연성을 보장한다. 일반적으로 데이터를 저장하고 소비 하는 방법을 정의하는 역할을 한다. 이 때문에 ML 모델의 작동방식과 데이터 흐름을 파악하고 있어야 한다. 또한 ML 모델 성능을 개선하는 새로운 기술을 도입하기 위한 지식도 요구된다.
- 장기적인 개선 사항을 찾기 위해 상황에 대한 이해가 필요.
- 각 사람과 팀의 요구 사항을 이해하고 적절한 리소스를 할당하는 능력.
Introducing MLOps (저자:Mark Treveil) 의 책을 읽고 MLOps에 대해 정리한 글이다. 더 자세한 내용을 알고 싶다면 MLOps 책 소개를 보길 바란다.