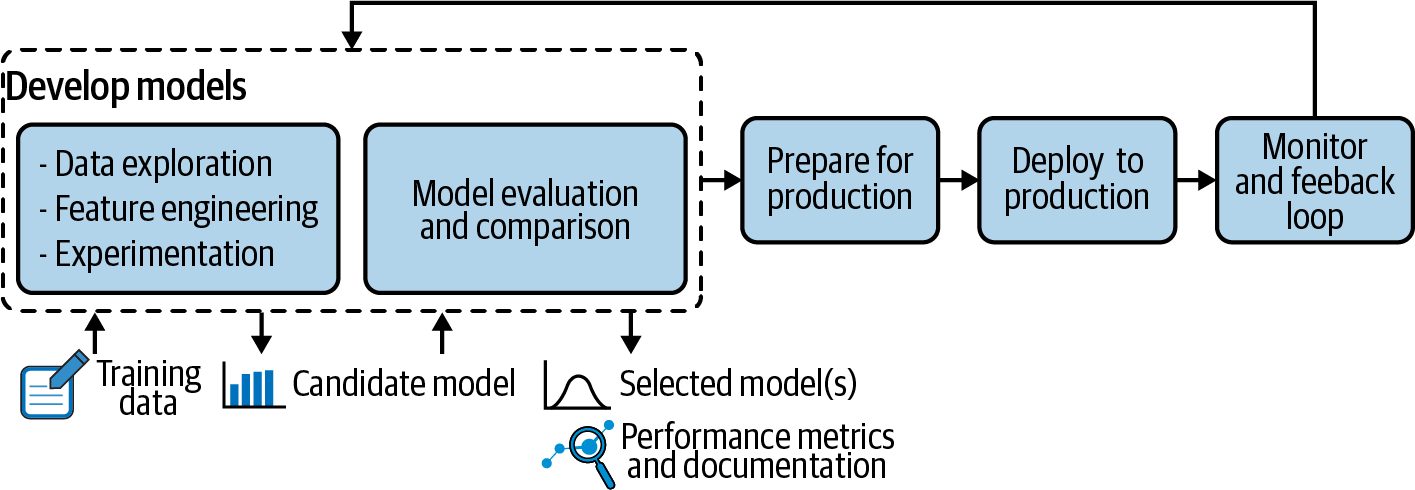
MLOps를 이해하기 위해서는 최소한 모델 개발 프로세스에 대한 이해가 필요하다. 아래 그림은 모델 개발 프로세스를 간단히 도식화한 그림이다. 이 장에서는 특히 MLOps의 맥락에서 모델 개발의 기본 사항을 살펴보고자 한다.
머신러닝 모델이란?
머신러닝 모델은 함수이다. 함수는 어떤 파라미터 즉, 입력(Input) 값을 전달하면 출력(Output) 값을 제공한다. 머신러닝도 이와 마찬가지다 그런데 일반적인 함수보다는 조금 더 복잡한 함수라고 생각하면 될 것이다.
필수 구성 요소
머신러닝 모델을 구축하려면 많은 구성 요소가 필요하다. 그 중 대표적인 요소에 대해 살펴보겠다.
-
학습 데이터머신러닝 모델을 학습 시키기 위해선 데이터가 필요하다. 예를 들어 고양이와 강아지를 분류하는 모델을 만들고 싶다면 강아지와 고양이 사진이 있어야한다.
-
평가 지표모델의 성능을 측정하고 싶다면 주제에 알맞는 평가 지표를 설정해야된다.
-
ML 알고리즘머신러닝에는 다양한 방식의 모델이 존재한다. 성능, 안정성, 계산 비용등 우선 순위를 정해서 상황에 맞는 알고리즘을 사용해야한다.
-
하이퍼 파라미터모델링할 때 사용자가 직접 세팅해주는 값이다. 예를 들어 Decision tree 모델에서 트리의 깊이를 조절할 수 있는 하이퍼 파라미터가 존재한다.
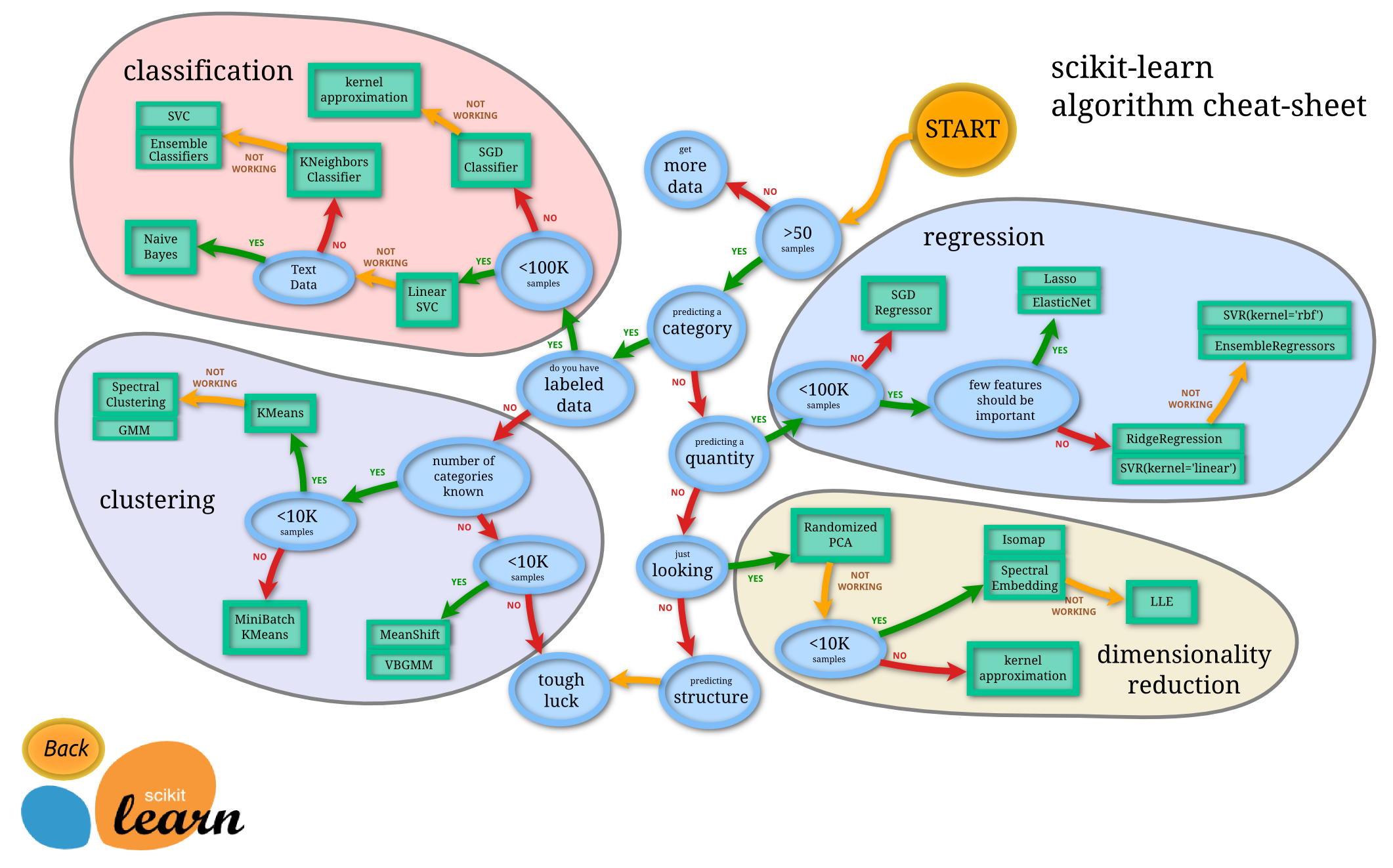
대표적인 ML 알고리즘
파이썬의 유명한 머신러닝 라이브러리인 사이킷런의 알고리즘 cheat-sheet를 보면 머신러닝 알고리즘의 큰 분류를 엿볼 수 있다. 여기에서는 회귀 분석(Regression), 분류(Classification), 군집(Clustering), 차원감소(Dimensionality Reduction)으로 크게 구분하고 있다.
데이터 탐색
데이터 사이언티스트는 모델 학습을 위한 데이터를 선택할 때 먼저 데이터를 탐색해야된다. 아무리 좋은 알고리즘이라도 데이터가 부적합 하다면 여러가지 문제가 발생할 수 있다. 효과적인 데이터을 고르기 위한 단계는 다음과 같다.
- 데이터 수집 방법과 어떤 가설이 세웠는지 문서화한다.
- 데이터 통계 요약을 살펴본다. 누락된 값이 있는지? 각 열의 도메인은 무엇인지?
- 데이터 분포를 자세히 살펴본다.
- 데이터 정제, 채우기, 필터링 등 전처리를 한다.
- 다중공성성 확인을 위해 각 피쳐 간의 상관 관계를 확인한다.
- 누락된 데이터가 있는지 확인한다.
하지만 데이터 분석에서 제일 중요한 요소는 해당 도메인 지식의 유무이다. 데이터에 대한 통찰력이 없다면 잘못된 판단을 내릴 확률이 높아지기 때문이다.
피쳐 엔지니어링 및 선택
사람은 데이터를 보고 직관적으로 판단할 수 있지만, 컴퓨터는 그렇지 못하다. 그래서 초기 데이터로부터 특징을 가공하여 모델에게 유용한 변수로 만들어주는 과정이 필요하다. Raw 데이터를 그대로 사용하는 것 보다 합리적인 가설을 통해 변수를 변형한다면 유의미한 결과를 도출할 수 있다. 다음은 피처 엔지니어링 방법의 예를 보여주고 있다.
-
파생변수기존의 정보에서 새로운 정보를 추론한다.
예) 이 날짜는 무슨 요일인가?
-
외부변수새로운 외부 정보를 추가한다.
예) 이 날짜의 날씨는 어땠는가?
-
인코딩동일한 정보를 다르게 제시한다.
예) 요일 또는 주중과 주말 분리
-
교차변수서로 다른 기능을 연결한다.
예) 날짜와 시간을 연결해서 평일-밤과 같은 정보를 생성.
피쳐 선택이 MLOps에 미치는 영향
피처 엔지니어링을 마쳤다면 피처 선택을 어떻게 해야되는 지에 대한 문제 남아있다. 많은 피처를 추가하면 정확한 모델이 생성되지만, MLOps에 많은 영향을 끼칠 수 있다.
- 모델을 계산하는 데 많은 시간과 비용이 소모된다.
- 피처가 많아지면 더 많은 유지 보수가 필요하다.
- 일부 안정성 손실을 발생 시킨다.
- 개인 정보 문제가 발생할 수 있다.
모델 실험
피처 선택까지 완료되었다면 이제 모델을 만들고 많은 실험을 통해 성능을 높여야한다. 예를 들면 알고리즘 내부의 하이퍼 파라미터를 튜닝하는 일이 있다. 더 나아가서 모델 개선을 위한 최선의 솔루션을 찾기 위해 다양한 모델을 실험한다. 실험 목표는 다음과 같다.
- 선택된 모델이 얼마나 유용한지 평가한다.
- 최적의 모델링 매개 변수 (알고리즘, 하이퍼 파라미터, 전처리 등)을 찾는다.
- 특정 항목에 대한 편향, 일반화 사이의 절충안을 정한다.
- 모델 개선과 계산 비용 사이의 균형을 찾는다.
위의 실험을 모두 진행하면 시간이 매우 많이 든다. 하지만 다행히도 모든 작업을 자동화 할 수 있는 플랫폼이 존재한다. AWS, GCP, Azure 등 머신러닝 클라우드에서 자동화된 AutoML을 활용한다면 효율적인 실험을 할 수 있을 것이다.
모델 평가 및 비교
머신러닝 모델에서 평가는 모든 프로젝트에서 필수적인 부분이다. 모델에 따라서 Accuracy를 사용할 때 만족스러운 결과를 줄 수 있지만, log_loss에서는 그렇지 못한 결과를 제공할 수 있다. 위에서 잠깐 언급했던 ML알고리즘에 따라 다양한 평가지표가 존재한다.
-
Classification Accuracy총 입력 데이터 수에서 정확한 예측 수의 비율
-
Logarithmic Loss모델이 예측한 확률 값을 직접적으로 반영하여 평가한다.
-
Confusion MatrixTraining 을 통한 Prediction 성능을 측정하기 위해 예측 value와 실제 value를 비교하기 위한 표이다.
-
Area under CurveAUC란 ROC 직선 아래 면적을 위미하고 1에 가까울 수록 성능이 좋다.
-
F1 Score정밀도와 재현율을 결합한 지표로서 둘 중 어느 한쪽에 치우치지 않았을 때 높은 값을 가진다.
-
Mean Absolute Error측정값에서 절대 오차의 크기를 평균낸 값이다.
-
Mean Squared Error오차의 제곱에 대해 평균을 취한 것이다. 작을 수록 원본과의 오차가 적다.
또한 검증 방법 또한 중요한 요소가 될 수 있다. 일반적으로 고정적인 training set을 사용하여 평가를 하는 경우 학습 데이터에 과적합 될 수가 있다. 그렇기 때문에 Validation set를 사용하여 모델의 성능을 검증하는 단계도 필요하다. 검증 방법의 대표적인 예는 다음과 같다.
-
holdout cross validation데이터셋을 train과 validation으로 나누어 사용하는 방법. 보통 8:2로 나누어 사용.
-
k-fold cross validation데이터셋을 K개의 그룹으로 나누어 그 그룹 중 하나를 validation set으로 사용하는 방법.
-
Leave-p-out cross validation데이터 셋에서 p개의 데이터를 추출하고 남은 데이터를 validation set으로 사용하는 방법.
버전관리 및 재현성
여러 버전의 모델을 구축하고 테스트를 반복하면서 모든 버전을 유지할 수 있어야한다. 모델의 재현성이 보장되어야 다른 버전의 모델끼리 비교를 할 수 있기 때문이다. 버전 관리 및 재현성은 두 가지 요구 사항을 해결한다.
- 실험 진행 중 막다른 골목에 막혔을 때, 이전 상태를 복원할 수 있다.
- 실험이 처음 수행 된 후 몇 년 후에도 같은 성능을 내도록 재생할 수 있다.
- 실험이 처음 수행 된 후 몇 년 후에도 같은 성능을 내도록 재생할 수 있다.
다행히도 버전 관리 및 재현성 또한 문서화 작업을 자동화 할 수 있다. 설계 및 배포를 위한 통합 플랫폼을 사용하면 구조화된 정보를 보장함으로써 재현성 비용을 줄 일 수 있다.
Introducing MLOps (저자:Mark Treveil) 의 책을 읽고 MLOps에 대해 정리한 글이다. 더 자세한 내용을 알고 싶다면 MLOps 책 소개를 보길 바란다.